




- @jwybobo2007
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
AV1编解码技术是一种先进的视频压缩标准,具有三大Profile配置(Main/High/Professional)和两级Tier层级。其核心特点包括:灵活的128×128超块划分结构、9种划分模式、先进的帧内/帧间预测技术、多符号算术熵编码、变换编码与量化技术,以及针对屏幕内容的优化编码。硬件方面,高通、苹果和英特尔等厂商的芯片已支持AV1硬解;软件生态包含libaom、dav1d等编解码器。码
1.服务端使用nodejs搭建,使用的module为express、nodejs-websocket。实现了简单的信令协商,代码如下:// server.jsvar ws = require("nodejs-websocket");var fs = require('fs');var https = require('https')var express = require('express');

在linux下开发时,可能会碰到不同库导出同名函数符号,导致行为异常的问题。举个例子:我的test.cpp需要链接以及,并且两个so库中都有一个同名的函数符号PrintInt,那在 test.cpp 中我想调用liba.so的PrintString时实际会调用函数符号呢?答案是根据链接顺序来。先链接先加载哪个库就会使用哪个库的符号。假设我们先链接加载的libb.so,那test实际会调用的就是li
Your PATH contains a literal "~", which works in some shells but will break when python tries to run subprocesses. Replace the "~" with $HOME.如果出现如上的错误,说明在 exportdepot_tools的路径时,使用了~符号来表示用户文件夹,而p...
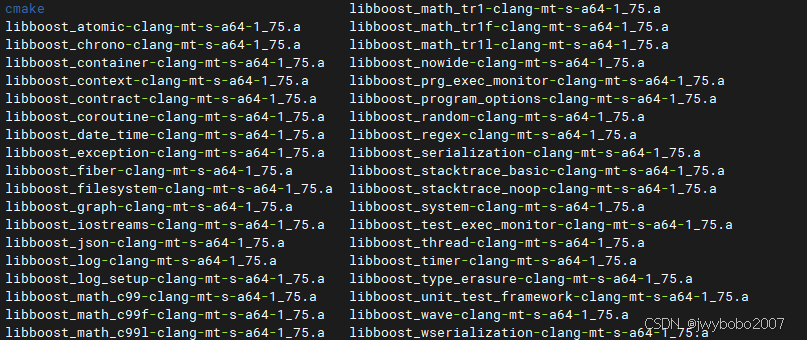
我在上一篇文章中介绍了curl和openssl的编译方式(),这篇再介绍一下boost库的编译。
我以官方给的WebRtc方式demo为例,实现了一个语音助手,其中包括指令设置以及tools的function使用,演示了如何触发tools指定的function,以此实现RAG以及更多功能。我们的提示词是通过它的instructions参数设置给模型的,另外它的tools参数是用来配置相关function的,需要注意的是tools目前还不支持mcp服务。在多模态大模型出现前,我们都是使用语音转文
在处理长音频文件的语音转文字任务时,单一文件的处理时长往往随着音频时长线性增长。为了优化整体处理效率,将大文件分割为多个小片段并采用并发处理策略能显著缩短总转换时间。这种分治方法是处理大规模音频数据的有效实践方案。对于带封装格式的音频文件比如mp3、opus、wav等,我写了一个基于ffmpeg实现的按时长进行分割的功能。文件分割方式一般有按固定时长和VAD(静音检测)检测两种,也可以将两者相结合
我在上一篇文章中介绍了curl和openssl的编译方式(),这篇再介绍一下boost库的编译。
是一个用相对路径表示的统一编译安装目录,openssl和curl都会引用以及安装到这个目录下,所以要保证两个开源库使用的编译脚本中的这个相对路径指向同一目录。如果有什么问题的话,也可以自己手动改成想要的路径,两个脚本一致就行。目前我编译的全部都是静态库,如果需要编译动态库的话,还需要调整下编译脚本中的参数。具体的参数可以查看openssl和curl的编译说明。curl使用的版本是 7.81。如果中
