




- @ipython_fool
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
快速掌握如何使用pip结合阿里云、腾讯云镜像源加速Python包的安装。本指南提供单次与永久加速设置,以及必备的pip命令详解,助您提升开发效率。

Claude Code 51万行源码“裸奔”:Anthropic 连夜社死,AI Agent 圈迎“天降开源”!

AI 终端工具满天飞,一会要写 SKILL.md,一会又要配 Subagent,包工头 Agent 到底是怎么管理这帮 AI 助手的?今天我们扒一扒 Claude Code 和 OpenCode CLI 里的底层逻辑。

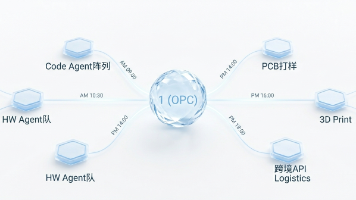
当 AI 智能体承包了从代码到硬件的全链路,程序员正将战场从 IDE 搬进华强北,以“一人公司”形态编排全球供应链,开启一人成军的硬核创业时代。
GitHub 爆火“灵魂提取”项目:从老板到永生 Skill,拆解高维空间里的赛博扫墓逻辑。

“教研究员做工程,比教工程师做研究更难。” 深度拆解 2 小时访谈:关于 AGI、强化学习与极客的自由意志。

本文复盘发版日内网环境下 Agent 调用工具频繁翻车的底层逻辑,并深入探讨 2026 年思考增强、DAG 并行调度及 MCP 协议如何重塑工业级 AI 生产力。

Claude Code 51万行源码“裸奔”:Anthropic 连夜社死,AI Agent 圈迎“天降开源”!
AI 终端工具满天飞,一会要写 SKILL.md,一会又要配 Subagent,包工头 Agent 到底是怎么管理这帮 AI 助手的?今天我们扒一扒 Claude Code 和 OpenCode CLI 里的底层逻辑。
国家数据局将 Token 定名“词元”,日调用量突破 140 万亿,标志着 AI 时代“度量衡”确立,开启万亿级智能经济新赛道。
