




- @interbigdata
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
t检验(Student's t test),主要依靠总体正态分布的小样本(例如n < 30)对总体均值水平进行差异性判断。t检验要求样本不能超过两组,且每组样本总体服从正态分布(对于三组以上样本的,要用方差分析,其他文章详述)。因。如果有不服从正态分布的情况,可以考虑使用和后面单独文章介绍。需要说明的是t检验还分为和,适用条件也各有不同,以下分别举例介绍。

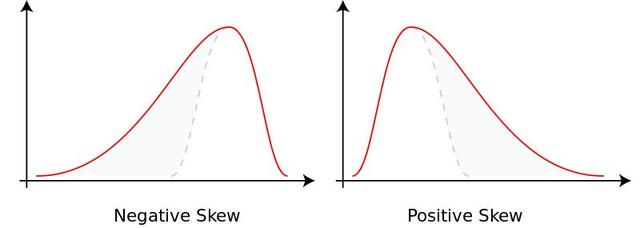
给定一组数据,我们怎么来判断业务的基本情况呢?此时我们主要用到两个统计学工具:集中趋势和离散趋势。1. 集中趋势集中趋势是一组数据的代表值,那用什么值作代表最有代表性呢?当然这个值应该和所有值差距不大是最好,此时我们首先想到的就是平均数,事实上,用来衡量集中趋势的最常用指标就是平均数,当然有时我们也使用中位数。平均数和中位数一般是不同的,除非样本呈正态分布。如果衡量集中趋势的指标选择不合理,...
相关性分析是量化不同因素间变动状况一致程度的重要指标。在样本数据降维(通过消元减少降低模型复杂度,提高模型泛化能力)、缺失值估计、异常值修正方面发挥着极其重要的作用,是机器学习样本数据预处理的核心工具。样本因素之间相关程度的量化使用相关系数corr,这是一个取之在[-1,1]之间的数值型,corr的绝对值越大,不同因素之间的相关程度越高——负值表示负相关(因素的值呈反方向变化),正值表示正相关..
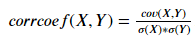
大多数情况下,我们都假设样本所在总体服从正态分布,然后使用t检验、方差分析等假设检验方法。但是总体如果不服从正态分布,那么就得使用非参数检验方法,如Mann-Whitney U检验和Wilcoxon秩和检验。其中Mann-Whitney U检验适用于独立双样本的情况,Wilcoxon秩和检验适用于配对双样本的情况。Mann-Whitney U检验和Wilcoxon秩和检验还支持单侧检验,来比较两组

首先,从技术角度来看,(1)卡方检验的样本涉及的因素(也就是变量)需要两个(含)以上,而且是定性变量(分类变量,定类变量),其值可以是数字,也可以符号,但是即使是数字也不具备数量的含义,只是用于区分。(2)其样本数据是由多个因素在不同水平(取值)情况下共同决定的数据,直观上表现为列联表(交互分类表,交叉表),形如下表。上表涉及的因素(变量)有两个,分别是地区和满意度,其值分别是[北京,上海]和[满

给定一组数据,我们怎么来判断业务的基本情况呢?此时我们主要用到两个统计学工具:集中趋势和离散趋势。1. 集中趋势集中趋势是一组数据的代表值,那用什么值作代表最有代表性呢?当然这个值应该和所有值差距不大是最好,此时我们首先想到的就是平均数,事实上,用来衡量集中趋势的最常用指标就是平均数,当然有时我们也使用中位数。平均数和中位数一般是不同的,除非样本呈正态分布。如果衡量集中趋势的指标选择不合理,...
在文本处理中,特征词是指那些出现在文本中的,用于区别该文本与其它文本不同的那些词。特征词起到表征(不是表达)该文本的作用。特征词也属于自然语言的范畴,未经规范化处理,也不受主题词表的控制。比如在语料库中,!这个字符仅出现在文本t中,那么!就可以作为文本t的特征词,尽管它并没有体现文本语义的作用。根据以上论述,我们可以看出,主题词可以理解为对关键词的规范化与精炼化的结果,是对整个文本高纯度提纯的结果
相关性分析是量化不同因素间变动状况一致程度的重要指标。在样本数据降维(通过消元减少降低模型复杂度,提高模型泛化能力)、缺失值估计、异常值修正方面发挥着极其重要的作用,是机器学习样本数据预处理的核心工具。样本因素之间相关程度的量化使用相关系数corr,这是一个取之在[-1,1]之间的数值型,corr的绝对值越大,不同因素之间的相关程度越高——负值表示负相关(因素的值呈反方向变化),正值表示正相关..
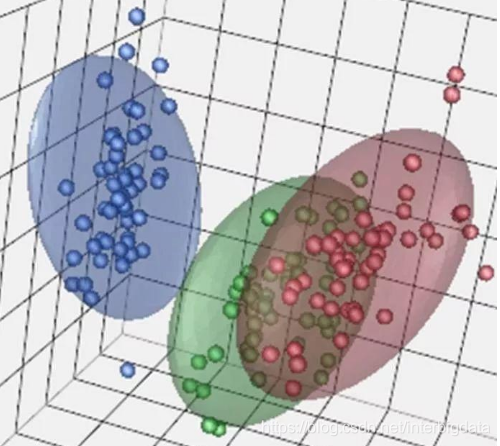
聚类与分类的不同在于,聚类所要求划分的类是未知的。也就是说我们对样本数据的划分是不了解。聚类分析的任务就是要明确这个划分。例如我们采集到很多未知的植物标本,并对每株标本的植物学特征进行了记录、量化。那么这些植物标本到底是几个物种呢?聚类分析就可以解决这个问题。当前在机器学习领域涌现了许多优秀的聚类分析算法供我们使用,如k-means、DBSCAN、AGNES等。通过使用这些成熟的算法,我们...
相关性分析是量化不同因素间变动状况一致程度的重要指标。在样本数据降维(通过消元减少降低模型复杂度,提高模型泛化能力)、缺失值估计、异常值修正方面发挥着极其重要的作用,是机器学习样本数据预处理的核心工具。样本因素之间相关程度的量化使用相关系数corr,这是一个取之在[-1,1]之间的数值型,corr的绝对值越大,不同因素之间的相关程度越高——负值表示负相关(因素的值呈反方向变化),正值表示正相关..