




- @hupanfeng
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
文章阐述了梯度下降法与误差反向传播法在神经网络训练中的应用。梯度下降法通过沿函数最陡方向迭代更新参数以最小化代价函数,但在神经网络中直接计算大量参数的导数会导致“导数地狱”。误差反向传播法通过引入神经单元误差δ,建立层间误差的递推关系,将复杂导数转化为矩阵运算,逐层反向传播误差(如输出层δ由误差项与激活函数导数计算,中间层δ由下一层δ与权重矩阵反向推导),显著降低了计算复杂度。
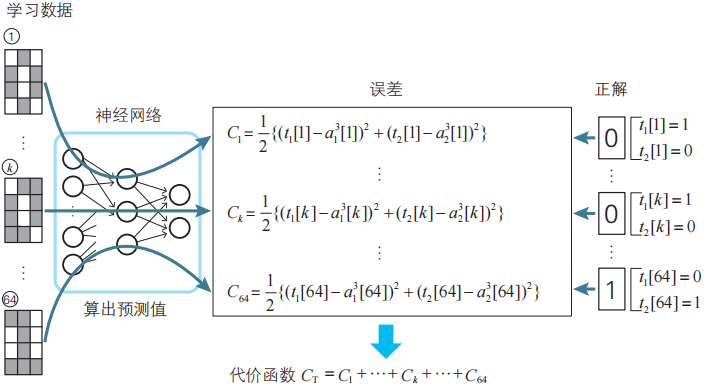
本文系统地阐述了神经网络中参数(权重和偏置)与变量的数学定义与区分,通过构建代价函数(如平方误差)并利用最优化方法调整参数以实现模型学习的过程,同时结合回归分析对比和Excel实例验证了学习机制。
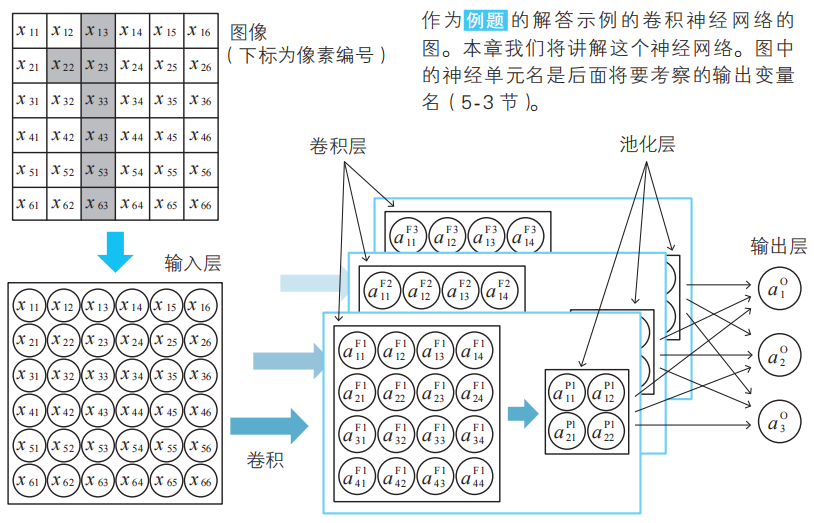
本文通过小恶魔的比喻和数学分析,阐述了卷积神经网络通过卷积层、池化层结构动态检测图像模式的方式,以及利用误差反向传播法和Excel实例验证其高效识别手写数字的实现原理与效果
本文系统梳理了神经网络所需的数学基础知识,涵盖函数、数列、向量、矩阵、导数、梯度下降法及回归分析等核心内容,为理解神经网络的底层原理与优化方法奠定理论基础。
在本章中,我们将探索多种具备多模态能力的LLMs及其在实际应用场景中的意义。首先,我们将通过改进原始Transformer技术,研究图像如何被转化为数值表示;接着,我们将展示如何通过这种Transformer扩展LLMs以涵盖视觉任务。
本文系统地阐述了神经网络中参数(权重和偏置)与变量的数学定义与区分,通过构建代价函数(如平方误差)并利用最优化方法调整参数以实现模型学习的过程,同时结合回归分析对比和Excel实例验证了学习机制。
现在我们已经对分词和词嵌入有了基本认识,接下来可以更深入地探讨语言模型的工作原理。本章我们将解析Transformer语言模型的核心技术原理,重点聚焦文本生成模型,以帮助读者特别加深对生成式大语言模型(LLMs)运作机制的理解。我们将同时探讨相关概念,并提供一些代码示例来演示这些原理。首先,我们将加载一个语言模型,并通过声明一个管道来为生成任务做好准备。在初次阅读时,可以选择跳过代码部分,集中精力
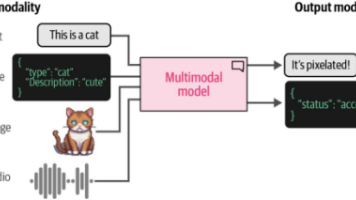
在本章中,我们将探索多种具备多模态能力的LLMs及其在实际应用场景中的意义。首先,我们将通过改进原始Transformer技术,研究图像如何被转化为数值表示;接着,我们将展示如何通过这种Transformer扩展LLMs以涵盖视觉任务。
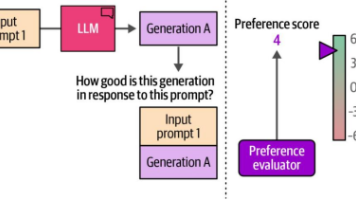
在本章中,我们将以一个预训练文本生成模型为例,详细讲解微调(fine-tuning)的完整流程。微调是生成高质量模型的关键步骤,也是我们工具包中用于将模型适配到特定预期行为的重要工具。通过微调,我们可以让模型适配特定的数据集或领域。本章将引导您了解两种最常见的文本生成模型微调方法:监督式微调(supervised fine-tuning)和偏好微调(preference tuning)。我们将深入
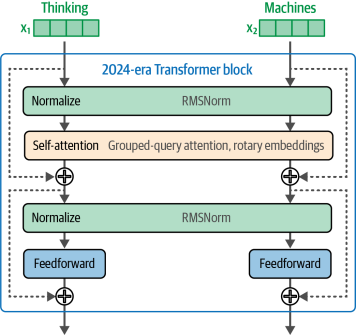
现在我们已经对分词和词嵌入有了基本认识,接下来可以更深入地探讨语言模型的工作原理。本章我们将解析Transformer语言模型的核心技术原理,重点聚焦文本生成模型,以帮助读者特别加深对生成式大语言模型(LLMs)运作机制的理解。我们将同时探讨相关概念,并提供一些代码示例来演示这些原理。首先,我们将加载一个语言模型,并通过声明一个管道来为生成任务做好准备。在初次阅读时,可以选择跳过代码部分,集中精力