- @heart_warmonger
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
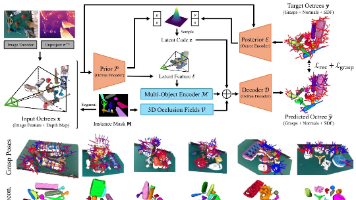
ZeroGrasp 是一篇面向零样本机器人抓取的 CVPR 工作,针对传统方法不建模 3D 几何易碰撞、多视图重建效率低等问题,提出单张 RGB-D 图像近实时联合 3D 重建与 6D 抓取位姿预测框架。它基于八叉树 CVAE 架构,引入多物体编码器与 3D 遮挡场建模空间关系与遮挡,提升遮挡场景重建精度,并通过接触约束与碰撞检测精修抓取位姿。论文构建了含 113 亿物理有效标注的大规模合成数据集
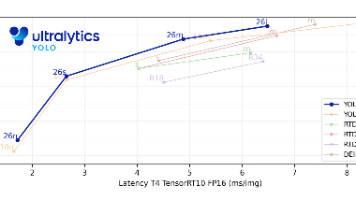
YOLO26作为YOLO系列最新成员,专为边缘和低功耗设备优化,带来四大核心突破:1)移除DFL简化边界框回归;2)首创端到端无NMS设计,CPU推理速度提升43%;3)引入ProgLoss和STAL策略提升小目标检测精度;4)采用MuSGD优化器加速训练收敛。该架构遵循简洁性、部署效率和训练创新三大原则,支持多任务和多种导出格式,显著降低边缘设备部署门槛。相比前代产品,YOLO26在保持精度的同
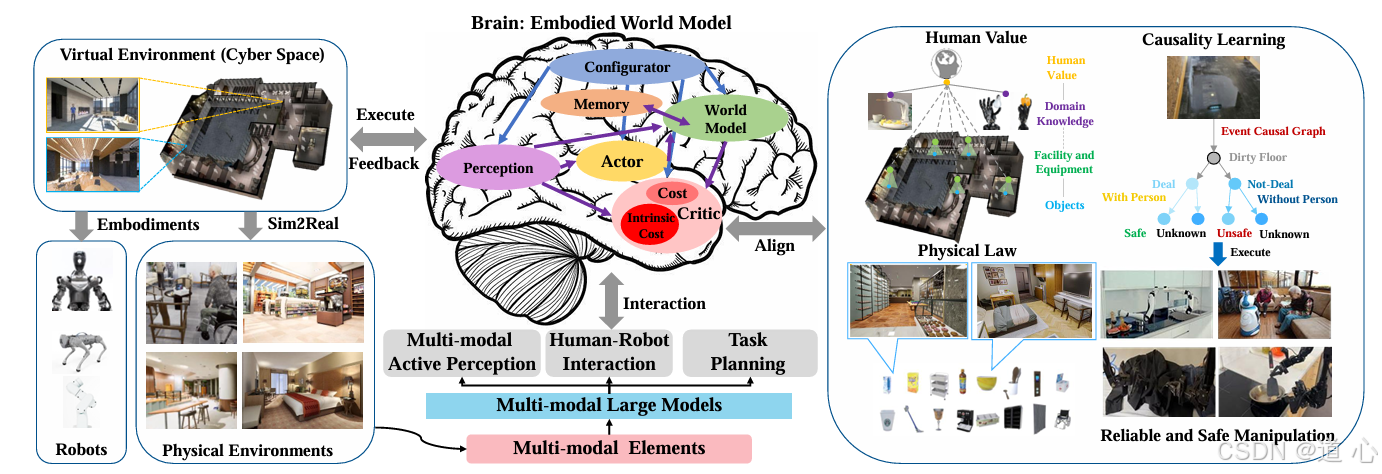
这篇论文《Aligning Cyber Space with Physical World: A Comprehensive Survey on Embodied AI》详细阐述了具身人工智能(Embodied AI)的发展现状,特别是在多模态大模型(MLM)和世界模型(WM)技术推动下的进展。具身人工智能被认为是实现通用人工智能(AGI)的关键途径之一。本文不仅深入探讨了具身感知、具身交互和具身
在深度学习项目中,训练多个模型版本以优化性能是常见的做法。随着模型数量的增加,手动验证每个模型的性能不仅耗时,而且容易出错。为了提高效率,自动化批量验证过程显得尤为重要。本文将介绍如何使用Python脚本批量运行YOLOv8模型的验证,并将验证结果组织到指定的文件夹中,方便后续分析和管理。遍历训练目录:自动查找所有包含文件的子文件夹。加载模型:使用Ultralytics YOLO库加载每个模型。运

本文介绍基于YOLOv8的区域计数系统,结合目标检测与ByteTrack跟踪算法,实现指定区域内物体实时计数。系统支持自定义多边形/矩形计数区域,可通过鼠标拖动调整位置,利用Shapely几何计算判断物体是否入区,结合跟踪ID避免重复计数。技术栈包含Ultralytics YOLOv8、OpenCV、Shapely等,具备检测框、跟踪轨迹与计数结果可视化功能,支持视频结果保存。适用于交通流量监控、

本文深入解析了 U-Net 模型的结构与应用,特别是在医学图像分割中的优势。我们介绍了 U-Net 的编码器、解码器及跳跃连接设计,阐述了卷积、池化、上采样等核心操作及损失函数(如 Dice 系数与交叉熵)。此外,提供了基于 PyTorch 的 U-Net 实现代码,涵盖数据预处理、模型训练、优化与评估。通过实际代码,读者可以了解如何高效训练 U-Net 模型,并应用于实际的图像分割任务。

最近几年,小目标检测成了计算机视觉落地的核心卡脖子难题——从遥感卫星影像识别地面小型违章建筑、无人机巡检捕捉电力线路上的微小缺陷,到安防监控识别远处的行人/车辆、自动驾驶感知路面的锥桶/井盖,这些像素尺寸通常小于32×32的“微小目标”,其检测精度直接决定了整个视觉系统能否安全、可靠落地。而小目标检测有一个核心痛点传统小目标检测模型,要么在空间域做简单的图像缩放/超分来提升特征,却引入大量背景噪声
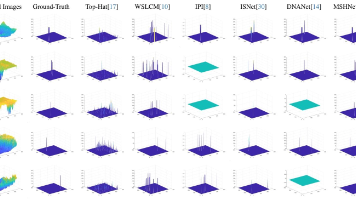
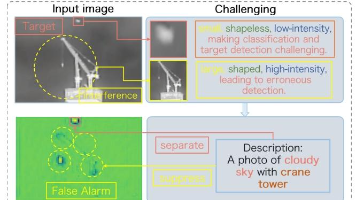
最近几年,红外小目标分割成了安防监控、军事侦察、无人机巡检、自动驾驶夜间感知等领域的核心感知技术——从边境线的夜间预警、无人机对地面小型目标的识别,到自动驾驶夜间识别道路上的碎石/落物,都需要能在复杂背景(如天空、树林、城市灯光)中精准分割出像素级尺寸的红外小目标。而红外小目标分割有一个核心痛点。
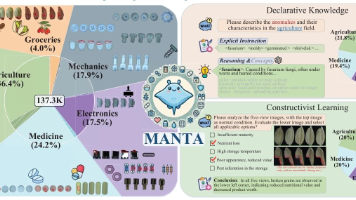
MANTA是面向微小物体的大规模多视图视觉-文本异常检测数据集,针对现有数据集单视角、无文本模态、难以适配微小物体检测的痛点构建。数据集覆盖农业、医药、电子、机械、杂货5大领域38类微小物体,含13.7万余张五视角高清图像,8617张异常图像带像素级标注,可完整覆盖物体表面。文本模块包含875条陈述性异常知识与2000道图文多选题,支撑视觉-文本联合学习。论文基于BLIP-2结合LoRA设计基线模
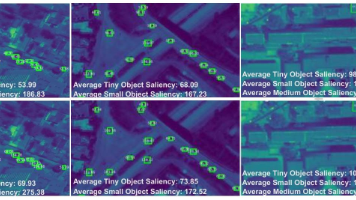
Infrared Small Target Detection with Scale and Location Sensitivity:不用复杂的算力消耗,只用 “多尺度金字塔特征增强 + 位置敏感上下文注意力 + 轻量级杂波抑制分支”,首次实现了尺度与位置敏感的红外小目标检测,既能自适应识别不同尺度的微小目标,又能在图像任意位置稳定检测,还能保证实时推理速度,大幅缩小了和实验室理想模型的性能差距