




- @haopinglianlian
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
方法工作原理优点缺点适用场景词袋模型(BOW)将文本表示为词频向量不考虑词序和上下文。简单直观,易实现,能够有效表示词频信息。忽略词序,生成高维稀疏向量。文本分类、信息检索TF-IDF基于词袋模型考虑词在文档中的频率以及整个语料库中的普遍性,赋予不同词权重。反映词的重要性,避免常见词主导影响,适用于文本分类。生成稀疏矩阵,无法捕捉词序和上下文关系。文本分类、关键词提取BM25基于 TF-IDF 的

本文提出Emu Video,这是一种文本到视频生成模型,将生成过程分解为两个步骤先根据文本生成图像;再基于文本和生成的图像生成视频。该模型在性能上超越了RunwayML的Gen2和Pika Labs等商业解决方案。
方法工作原理优点缺点适用场景词袋模型(BOW)将文本表示为词频向量不考虑词序和上下文。简单直观,易实现,能够有效表示词频信息。忽略词序,生成高维稀疏向量。文本分类、信息检索TF-IDF基于词袋模型考虑词在文档中的频率以及整个语料库中的普遍性,赋予不同词权重。反映词的重要性,避免常见词主导影响,适用于文本分类。生成稀疏矩阵,无法捕捉词序和上下文关系。文本分类、关键词提取BM25基于 TF-IDF 的
目前的视频生成方法主要侧重于文本到视频的生成,这样生成的视频片段往往动作极少。作者认为,仅依赖文本指令进行视频生成是不够且并非最优的。在本文中,作者介绍了PixelDance,这是一种基于扩散模型的新颖方法,它将视频生成的第一帧和最后一帧的图像指令与文本指令相结合。Emu Video根据输入文本提示生成图像;之后再基于图像和文本的强条件生成视频。输入的内容包括,文本,作为视频第一帧的图像,作为视频
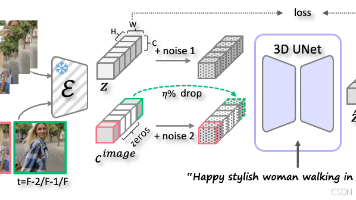
论文提出了稳定的潜在视频扩散模型(Stable Video Diffusion),这是一种用于高分辨率、最先进的文本到视频和图像到视频生成的视频扩散模型。最近的视频生成模型中,常见的手段是在二维图像的潜在扩散模型中插入时间层,并在小规模高质量视频数据集上进行微调,进而转化为视频生成模型。这些方法训练方法差异很大整理视频数据的策略并未达成共识,这是本文主要解决的问题之一。在本文中,评估了训练视频潜在

Meta的Emu Video模型通过分解式生成方法,将文本到视频(T2V)任务拆分为文本生成图像(T2I)和图像+文本生成视频两个步骤。该模型基于预训练的潜在扩散模型,采用图像条件增强策略,结合噪声调度优化与多阶段训练,在保持T2I模型多样性的同时提升视频生成质量。实验表明,Emu Video在512分辨率视频生成上超越RunwayML Gen2等商业方案,支持单图+文本输入,并通过用户研究验证了

方法类别原理常见方法优点缺点适用场景过滤法(Filter Methods)独立于模型,基于统计指标对特征评分,并选择得分较高的特征。- 方差选择法:剔除方差较小的特征- 皮尔森相关系数:选择线性相关性高的特征- 互信息:选择信息增益大的特征计算效率高,易于实现未考虑特征间相互作用,可能遗漏重要的组合特征快速预筛选大量特征的情况,适合初步筛选特征包裹法(Wrapper Methods)通过训练模型评
算法原理优点缺点适用场景GD梯度下降算法,通过每次使用整个训练集,或者SGD和MGD。计算损失函数相对于模型参数的梯度沿着梯度下降的方向更新参数,以最小化损失函数。理论稳定,易于实现计算成本高,特别是在大数据集上更新缓慢小规模数据集或批量处理场景Momentum在 SGD 基础上增加动量,不仅考虑当前的梯度,还利用过去的梯度积累,加入惯性来加速收敛并减少震荡。提升收敛速度、减少震荡需调节动量系数数

激活函数优点缺点适用场景Sigmoid平滑输出,适合二分类问题梯度消失,非零中心二分类输出层Tanh零中心输出,平滑梯度消失中间层或输出层ReLU计算简单,减轻梯度消失死神经元问题,不对称输出深层网络,特别是卷积神经网络(CNN)Leaky ReLU解决 ReLU 死神经元问题,保持梯度流动不一定总是比 ReLU 更好需要避免死神经元问题的深层网络PReLU可学习的负斜率,灵活性高增加了模型的复杂

本文介绍了机器学习的特征工程方法,包括特征提取和特征选择两大核心内容。在特征提取部分,详细讲解了手工特征提取(文本、图像、时间序列数据的处理方法)和自动特征提取(CNN、RNN、BERT等深度学习方法)。在特征选择部分,系统分析了过滤法、包裹法和嵌入法三类方法的原理、优缺点及适用场景,并提供了总结表格对比。文章还简要提及了正则化方法和强化学习的概念,为机器学习实践提供了全面的特征处理指导。
