




- @gm0012
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
爬取三国演义小说中的所有章节标题和章节内容import requestsfrom bs4 import BeautifulSoup# UA伪装headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 S
加载数据import numpy as npimport pandas as pddata = pd.read_csv('iris.csv')# 去掉不需要的ID列data.drop('ID',axis=1,inplace=True)# 删除重复记录data.drop_duplicates(inplace=True)##进行映射de = data['Species'].drop_duplicate
K-means是一种最流行的聚类算法 属于无监督学习可以在数据集分为相似的组(簇),使得组内数据的相似度较高,组间之间的相似度较低步骤:# 1 从样本中选择k个点作为初始簇中心# 2 计算每个样本到各个簇中心的距离,将样本换分到距离最近的簇中心所对应的簇中# 3 根据每个簇中所有样本,重新计算簇中心,并更新# 4 重复步骤2 3 直到簇中心的位置变化小于指定的阈值或者达到最大迭代次数为数据读取im
线性 回归数据集分析#CRIM:城镇人均犯罪率。ZN:住宅用地超过 25000 sq.ft. 的比例。INDUS:城镇非零售商用土地的比例。CHAS:查理斯河空变量(如果边界是河流,则为1;否则为0)。NOX:一氧化氮浓度。RM:住宅平均房间数。AGE:1940 年之前建成的自用房屋比例。#DIS:到波士顿五个中心区域的加权距离。#RAD:辐射性公路的接近指数。#TAX:每 10000 美元的全值
K-means是一种最流行的聚类算法 属于无监督学习可以在数据集分为相似的组(簇),使得组内数据的相似度较高,组间之间的相似度较低步骤:# 1 从样本中选择k个点作为初始簇中心# 2 计算每个样本到各个簇中心的距离,将样本换分到距离最近的簇中心所对应的簇中# 3 根据每个簇中所有样本,重新计算簇中心,并更新# 4 重复步骤2 3 直到簇中心的位置变化小于指定的阈值或者达到最大迭代次数为数据读取im
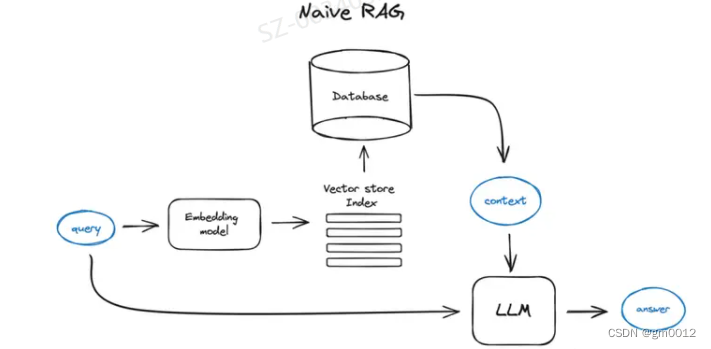
检索增强生成(Retrieval Augmented Generation,简称RAG)为大型语言模型(LLMs)提供了从某些数据源检索到的信息,以此作为生成答案的基础。简而言之,RAG是搜索+LLM提示的结合,即在有搜索算法找到的信息作为上下文的情况下,让模型回答提出的查询。查询和检索到的上下文都被注入到发送给LLM的提示中。
K-means是一种最流行的聚类算法 属于无监督学习可以在数据集分为相似的组(簇),使得组内数据的相似度较高,组间之间的相似度较低步骤:# 1 从样本中选择k个点作为初始簇中心# 2 计算每个样本到各个簇中心的距离,将样本换分到距离最近的簇中心所对应的簇中# 3 根据每个簇中所有样本,重新计算簇中心,并更新# 4 重复步骤2 3 直到簇中心的位置变化小于指定的阈值或者达到最大迭代次数为数据读取im