




- @ggggjatihc
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:本文介绍了在麒麟Linux系统(x86_64架构)上安装Docker并部署PostgreSQL的完整流程。首先确认CPU架构并下载对应版本的Docker安装包,然后从华为镜像源获取PostgreSQL 16.10的tar包并导入。在运行容器时遇到"unable to find image"错误,解决方法是通过镜像ID直接启动容器。整个过程包括:系统架构确认、Docker安
这篇文章探讨了知识切片在RAG流程中的关键作用,分析了传统切片方法(固定长度、段落、句子、滑动窗口、递归切片)的缺陷,包括语义断裂、主题混杂、上下文丢失等问题。作者指出这些方法无法真正理解语义边界,导致检索效果不稳定。文章提出了语义切片的概念,通过计算句子间相似度来识别主题边界,实现更精准的知识组织。这种方法能避免生硬切割,保持语义完整性,从而提升后续向量化和检索的效果。

这篇文章深入浅出地介绍了多模态检索中的CLIP模型及其应用。主要内容包括: 多模态检索的核心挑战:将文本和图片编码到同一向量空间进行比较 CLIP模型的原理:通过对比学习将4亿对图文数据映射到统一空间 实际应用演示:如何使用CLIP实现"输入文字搜图片"的功能 技术实现细节:包括向量预计算、相似度匹配和结果排序 文章通过生动的比喻(如"世界语翻译官")和具体

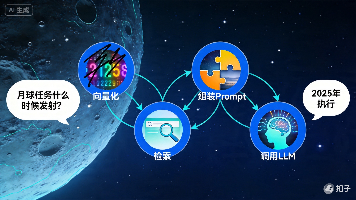
本文介绍了一个完整的RAG(检索增强生成)系统的工作流程。RAG系统通过将用户问题转化为向量,在向量数据库中检索最相关的知识片段,然后将其与问题一起输入大语言模型生成精确回答。文章以"月球任务发射时间"为例,展示了从问题向量化、相似度计算到最终答案生成的完整过程,并提供了代码实现的关键步骤。相比直接将整个知识库输入模型,RAG通过智能检索显著提高了回答效率和准确性。
本文介绍了三种为AI系统提供知识的方法:提示词工程、传统数据库和向量数据库。作者通过眼科医生案例说明,当知识库增大时,提示词工程会因长度限制失效,传统数据库则无法理解语义。向量数据库通过将文本转化为向量并计算相似度,实现了语义理解和智能匹配。文章详细讲解了如何实现一个简易向量数据库,包括文档插入、ID查询和核心的相似度搜索功能,并提供了余弦相似度计算的代码示例。这种方案完美解决了大知识库场景下的语

本文介绍了一个基于Go语言和Ollama构建的轻量级RAG系统,专为非技术背景的眼科医生客户设计。系统采用提示词工程方式,将本地知识库(txt文件)与用户问题结合后通过Ollama调用DeepSeek模型生成回答,省去了复杂的数据库设置。项目结构简单,包含知识库加载、Ollama接口调用等核心功能模块,支持通过配置文件调整运行参数。安装只需下载Ollama、DeepSeek模型并编译运行Go代码即
本文介绍了一个基于Go语言和Ollama构建的轻量级RAG系统,专为非技术背景的眼科医生客户设计。系统采用提示词工程方式,将本地知识库(txt文件)与用户问题结合后通过Ollama调用DeepSeek模型生成回答,省去了复杂的数据库设置。项目结构简单,包含知识库加载、Ollama接口调用等核心功能模块,支持通过配置文件调整运行参数。安装只需下载Ollama、DeepSeek模型并编译运行Go代码即
本文通过阿尔忒弥斯2号登月任务案例,通俗讲解AI如何通过文本向量化理解人类语言。核心原理是将文字转换为数字向量,包括五个步骤:文本清洗(去除噪音)、分词处理(提取关键词)、词频统计、构建向量(按词汇表顺序排列词频)、向量归一化(L2归一化使向量长度为1)。文章提供了完整的Go语言实现代码,演示如何将"阿尔忒弥斯2号"新闻片段转化为[0.35,0.71,0.35,0,0,0,0,
