




- @firehadoop
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
数据流向Prefill:所有输入token并行通过所有层Decode:一次只有一个新token通过所有层缓存使用Prefill:创建KV缓存Decode:利用已有KV缓存计算模式Prefill:批量处理Decode:自回归处理二、 Prefill阶段的目标与工作原理Prefill阶段的核心目标是将理解用户输入token的含义,生成输出第一个token,是后续decode阶段的首个输入。三、举例说明
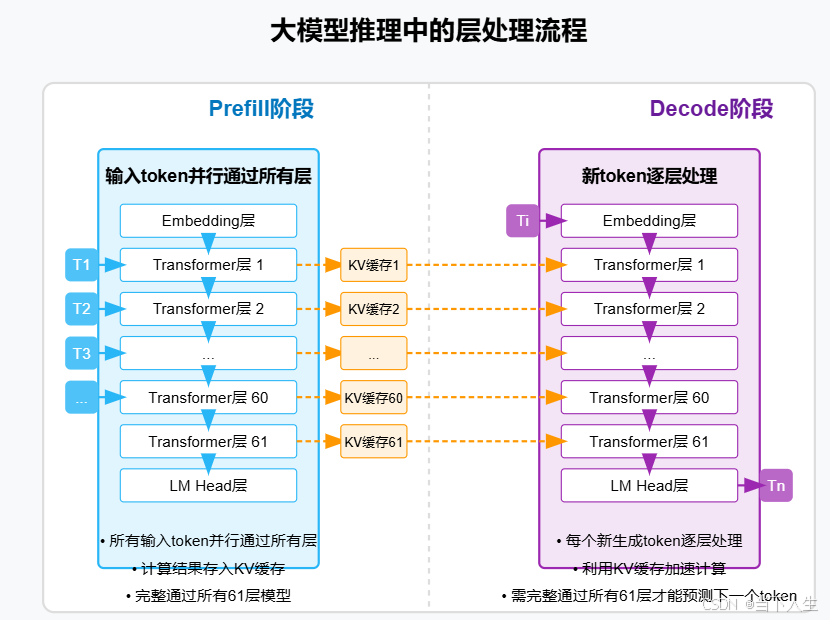
DeepSeek R1 采用了混合专家(Mixture of Experts,MoE)架构,包含多个专家子网络,并通过一个门控机制动态地激活最相关的专家来处理特定的任务。延迟是此阶段的关键问题。在分布式环境中,不同的节点可以并行处理输入的不同片段或不同的层,从而可能显着提高速度。在推理期间,当一个 token 被路由到一组特定的 8 个专家时,只有托管这些专家的节点才需要执行涉及其参数的大量计算。

2017年在省公司做一个项目,涉及到一个亿级别的大表操作,过程中遇到了很多坑,走过后记录如下,方便今后回忆。Oracle数据库是一种事务性数据库,对删除、修改、新增操作会产生undo和redo两种日志,当一次提交的数据量过大时,数据库会产生大量的日志写文件IO操作,导致数据库操作性能下降,尤其是对一张记录过亿的表格进行操作时需要注意以下事项: 1、操作大表必须知道表有多大selec...
上一篇文章介绍了如何通过docker的基本操作命令搭建运行一个zabbix系统,搭建运行zabbix涉及到了多个容器组成。操作起来相对繁琐,并且每次运行都要来一遍,很是不方便。 使用Docker Compose,不再需要使用shell脚本来启动容器。在配置文件中,所有的容器通过services来定义,然后使用docker-compose脚本来启动,停止和重启应用,和应用中的服..
一、zabbix可以干什么Zabbix 是由 Alexei Vladishev 开发的一种网络监视、管理系统,基于 Server-Client 架构。可用于监视各种网络服务、服务器和网络机器等状态。Zabbix 使用 MySQL、PostgreSQL、SQLite、Oracle 或 IBM DB2 储存资料。Server 端基于 C语言、Web 前端则是基于 PHP 所制作的。Zabbix...
一、实验目标安装三台centos7虚拟机,组建hadoop实验集群,centos是从centos7官网下载的最新版本,默认系统安装,创建hadoop用户组,新建用户hadoop并加入hadoop组。二、实验环境介绍三台机器的网络主机配置如下:192.168.10.166 master192.168.10.167 slave01192.168.10.168 slave02
随着公有云资源的普及越来越多的人或单位在各种公有云上安了家,云虽然很好,但公有云资源如何安全快捷的访问本地局域网内资源呢?本文的目标是解决你的混合云组网,将公有云网络通过IPSEC-VPN技术打通与本地局域网的互联,实现混合云组网。 混合云组网是大势所趋,各个公有云服务商也都提供了相应的收费服务,我查了一下,在天翼云中利用IPSEC-VPN打通网络实现互联的产品叫做‘云网..
天翼云通过910b部署deepseek r1 70b蒸馏模型

上一篇文章介绍了如何通过docker的基本操作命令搭建运行一个zabbix系统,搭建运行zabbix涉及到了多个容器组成。操作起来相对繁琐,并且每次运行都要来一遍,很是不方便。 使用Docker Compose,不再需要使用shell脚本来启动容器。在配置文件中,所有的容器通过services来定义,然后使用docker-compose脚本来启动,停止和重启应用,和应用中的服..
一、YUM代理方案使所有yum操作都能使用代理服务器,请在中指定代理服务器详细信息 /etc/yum.conf。该proxy 设置必须将代理服务器指定为完整URL,包括TCP端口号。如果您的代理服务器需要用户名和密码,请通过添加proxy_username和 proxy_password设置指定这些 。下面的设置允许yum使用代理服务器 mycache.mydomain.com连接到端口3...