




- @f2424004764
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文详细介绍了如何使用Cloudflare AI Gateway代理第三方大模型服务。主要内容包括:1) AI Gateway的功能特性,如日志分析、缓存、限速、重试机制等;2) 具体配置步骤,从创建网关到对接自定义模型服务商;3) 实战演示以DMXAPI为例,展示如何通过curl请求代理服务。教程提供了完整的参数配置指南和截图说明,帮助用户快速实现大模型服务的代理接入,同时利用Cloudflar
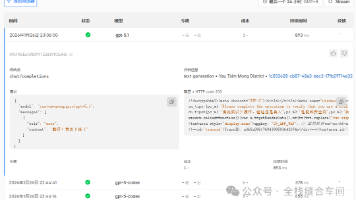
base_url为:http://host.docker.internal:11434/v1 这个向量模型也是我们之前安装好的。我们进到ollama的向量模型列表:https://ollama.com/search?打开ollama的官网进行下载: https://ollama.com/download。ollama支持的模型如下: https://ollama.com/search。docekr
本文系统梳理了 Claude 的核心扩展能力,包括 MCP 服务的安装与卸载机制、Subagent 与 Skills 的区别与适用场景,以及 Plugin 的整体打包能力。通过实际案例说明,不同工具在上下文管理和任务处理中的差异,并展示 frontend-design 插件对前端生成效果的提升,帮助开发者快速理解并高效使用 Claude 的扩展生态。

欢迎大家使用我的小程序新上线的人像转动漫功能:微信搜索《一方云知》,找到小程序后拉到最下面有一个人像转动漫的图标,点进去就可以用啦,目前是免费使用哦。前端框架我用的uview,所以我在页面简单使用了uview的上传组件,拿到图片本地路径后再转成base64,腾讯云的api接口在云对象里调用。想要了解更多相关知识,可以查看我以往的文章,其中有许多精彩内容。腾讯云的这个API Explorer功能还挺

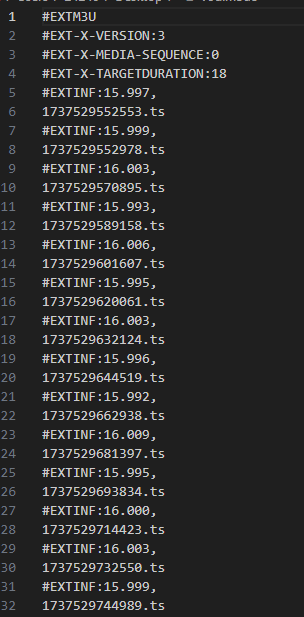
m3u8的视频如果通过一般的下载器,可能只会下载下来一个m3u8的文件,可能有时候需要在代码里下载m3u8的视频
简单来说,就是可以将错误格式(非标准)的json修正

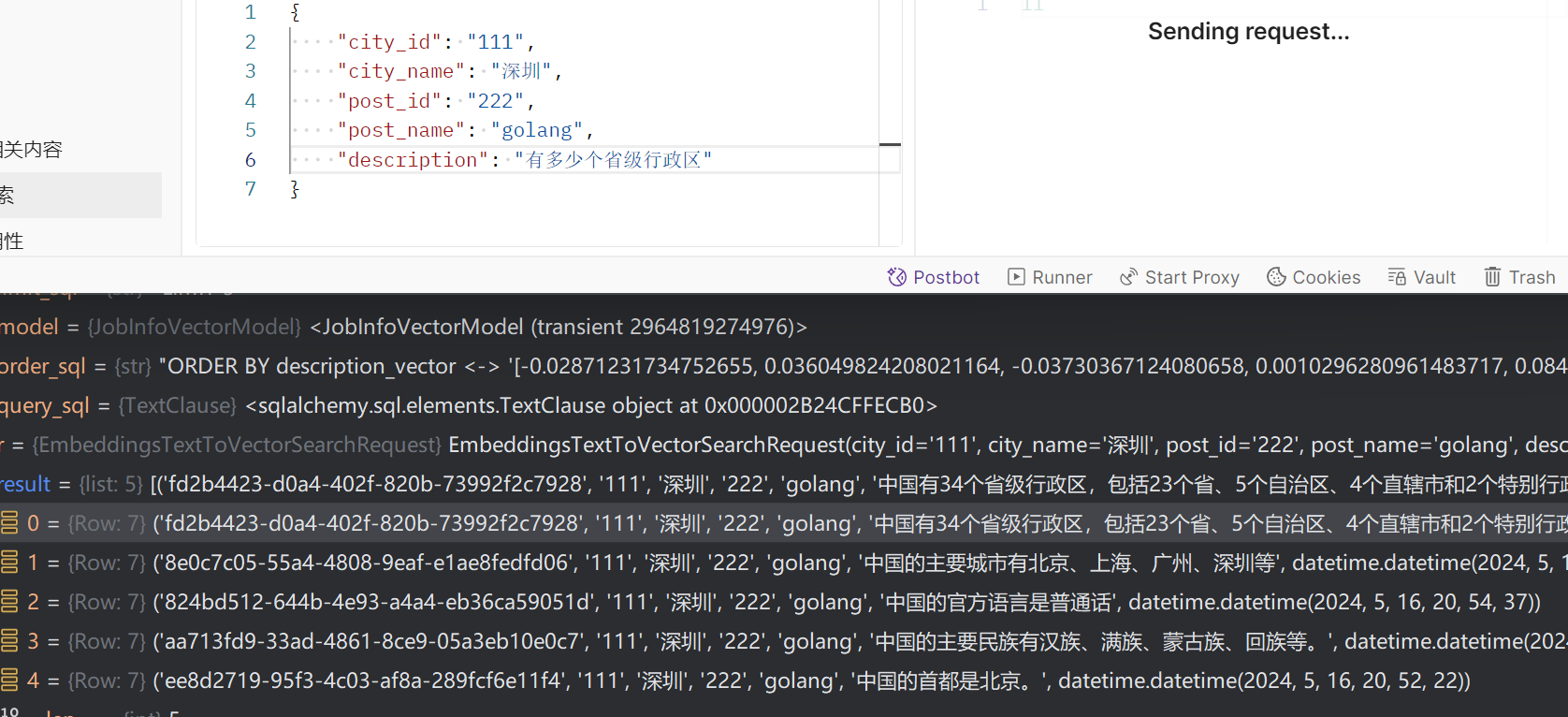
再提供一个查询的接口,这个接口先把传入的文本转成向量,再去pgsql向量数据库查询,最后得出结果,表结构就是文本对应向量,然后查询的时候根据向量文本相似度查询相似度最高的几条记录,这样就可以拿到文本了,再将这个文本丢给AI作参考,然后AI就可以先基于本地内容回答了。rag我简单理解来看就是我先有一段文本,先把它转成向量,保存到向量数据库中,下次我调用llm时将向量数据库中查询的结果给llm作参考并
所以现在的大概流程是:先上传文件到阿里云的对象存储,拿到图片地址后传给阿里云的人像动漫化接口,再有一个定时任务去删除这些上传的图片文件,大概保存1天左右。太难了,个人你要是想做AI的东西,直接一刀切了,我之前还做过接入微软的azure openai,微信审核直接给我拒绝了,不管你怎么提交说明都没用。想着之前腾讯云报错是因为线上环境NodeJs版本问题,索性就将线上NodeJs版本该高一点,结果当前

逻辑还是比较简单的,一个while循环,每次查找20条已过期的数据,如果没有则结束while循环,存在则进入for循环删除,分别记录删除成功、失败的数量,但是有个问题,如果一直删除失败,那么就会一直陷入死循环了。下一期文章我将继续完善两个通道之间的切换问题,以及页面的控制可以通过配置更改,如:两个通道的启用、通道二的风格选项的启用、每个通道的分享标题和图片等等配置。实现:使用while循环,在循环

欢迎大家使用我的小程序新上线的人像转动漫功能:微信搜索《一方云知》,找到小程序后拉到最下面有一个人像转动漫的图标,点进去就可以用啦,目前是免费使用哦。前端框架我用的uview,所以我在页面简单使用了uview的上传组件,拿到图片本地路径后再转成base64,腾讯云的api接口在云对象里调用。想要了解更多相关知识,可以查看我以往的文章,其中有许多精彩内容。腾讯云的这个API Explorer功能还挺