- @dzysunshine
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
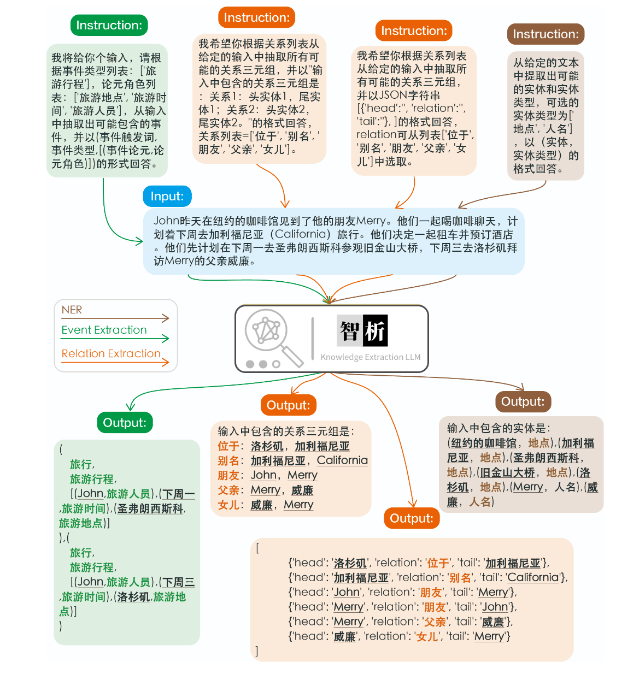
KnowLM 是由浙江大学NLP&KG团队的在读博士生研发并开源的项目,是一种将LLM与知识图谱结合的知识抽取大模型,主要包含的任务有命名实体识别(NER)、事件抽取(EE)、关系抽取(RE)。围绕知识和大模型,用构建的中英双语预训练语料对大模型如LLaMA进行全量预训练基于知识图谱转换指令技术对知识抽取任务,包括NER、RE、IE进行优化,可以使用人类指令来完成信息抽取任务用构建的中文指令数据集

将alpaca-combined下的文件都放到7B目录下后,执行下面的操作。工具为例,介绍无需合并模型即可进行本地化部署的详细步骤。使用text-generation-webui搭建界面。我们进一步将FP16模型转换为4-bit量化模型。将合并后的模型权重下载到本地,然后传到服务器上。会显示:7Btokenizer.model。会生成ggml-model-f16.bin。1、先新建一个conda环

文章目录1. 分别使用两个版本对同一个数据集进行测试1.1 数据集的准备1.2 用两个版本设定相同的参数,对数据集进行训练1.3 将评估结果打印出来2. 两个版本的区别参考看过别人使用Xgboost会发现它是由有两个版本的,分别是xgboost的python版本有原生版本和为了与sklearn相适应的sklearn接口版本,现在就简单总结下二者的区别。这里放上Xgboost中文文档,以及XGB..
北大团队发布首个的中文法律大模型落地产品ChatLaw,为大众提供普惠法律服务。模型支持文件、语音输出,同时支持法律文书写作、法律建议、法律援助推荐。

北大团队发布首个的中文法律大模型落地产品ChatLaw,为大众提供普惠法律服务。模型支持文件、语音输出,同时支持法律文书写作、法律建议、法律援助推荐。
KnowLM 是由浙江大学NLP&KG团队的在读博士生研发并开源的项目,是一种将LLM与知识图谱结合的知识抽取大模型,主要包含的任务有命名实体识别(NER)、事件抽取(EE)、关系抽取(RE)。围绕知识和大模型,用构建的中英双语预训练语料对大模型如LLaMA进行全量预训练基于知识图谱转换指令技术对知识抽取任务,包括NER、RE、IE进行优化,可以使用人类指令来完成信息抽取任务用构建的中文指令数据集

北大团队发布首个的中文法律大模型落地产品ChatLaw,为大众提供普惠法律服务。模型支持文件、语音输出,同时支持法律文书写作、法律建议、法律援助推荐。
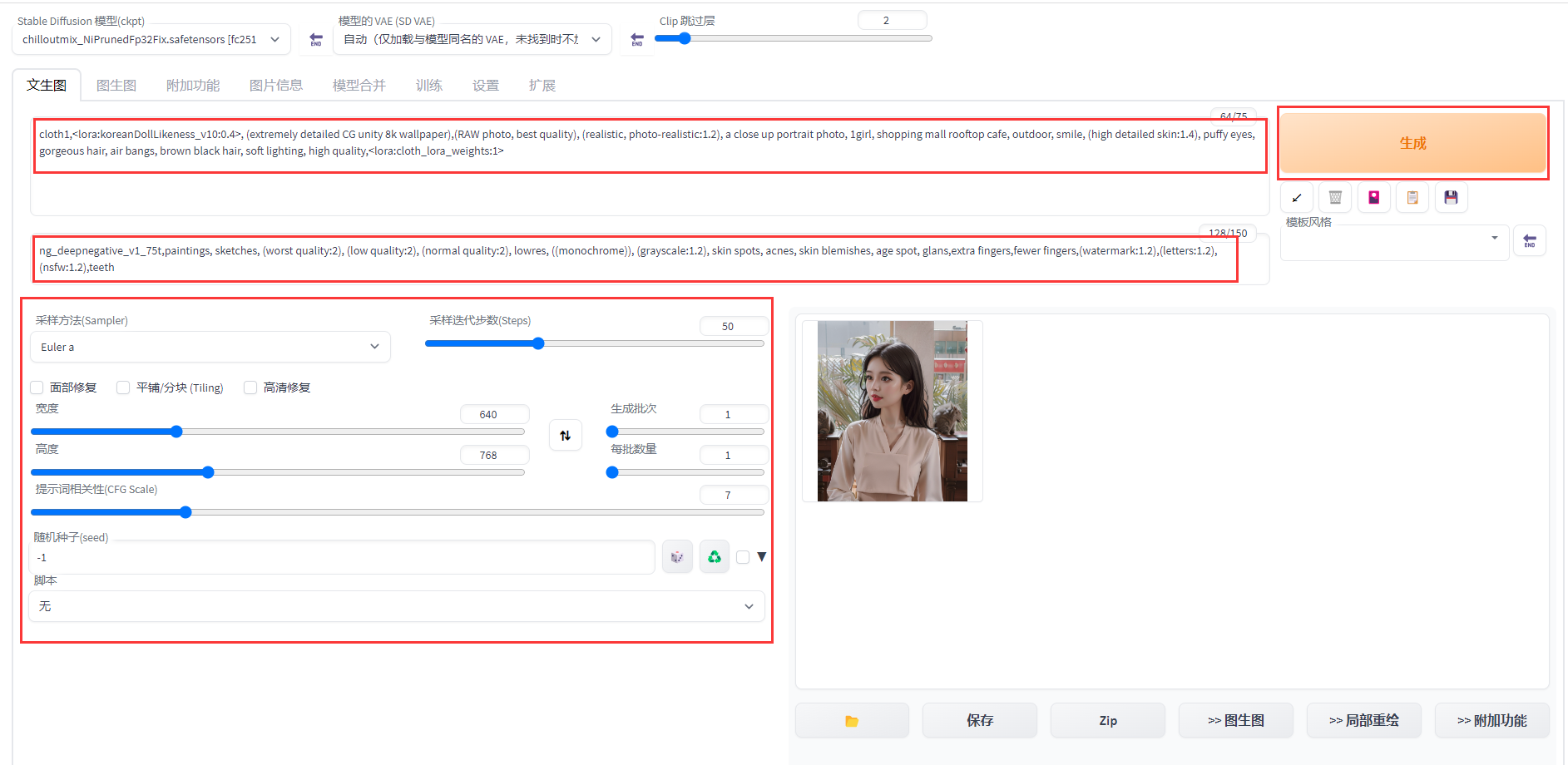
Stable Diffusion 是一种文本到图像的潜在扩散模型,由 Runway 和慕尼黑大学合作构建,第一个版本于 2021 年发布。目前主流版本包含 v1.5、v2和v2.1。它主要用于生成基于文本描述得详细图像,也应用于其他任务,如修复图像、生成受文本提示引导的图像到图像的转换等。本文主要讲解如何免费在**阿里云交互式建模(PAI-DSW)**中基于LoRA微调并部署 Stable Dif