- @devascend
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
亲爱的开发者! 向大家发出专属邀请~ 诚邀您参加鲲鹏昇腾开发者大会 2026 无论是想触摸最新计算底座的脉搏 还是与行业顶尖专家面对面 探讨 Agentic AI 的未来 KADC 2026 都将是您不能错过的技术盛会! 【鲲鹏昇腾开发者社区】点击进入专属报名入口

敏捷开发,一触即达!

模型减负,高效部署!

化繁为简,训练加速!

阐述大模型量化的基本概念,重点讲解W8A8、W4A8及稀疏量化等量化技术的原理与适用场景。

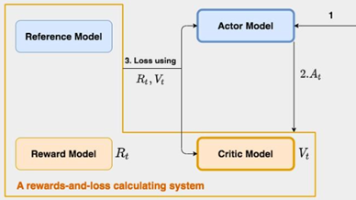
RLHF-PPO 昇腾训推共卡方案案例总结(下)
RLHF-PPO 昇腾训推共卡方案案例总结(上)
方向:CANN开源集成1 CANN7升级CANN8踩坑实录:解决HCCL超时与性能回退问题2 CANN 开源仓核心模块解析:仓库结构与功能定位深度剖析3 CANN 8 性能实测与优化:通信算子变化带来了什么?4 CANN 7升级到CANN 8常见问题与性能分析测评5 昇腾 CANN 开源仓核心模块深度解析:仓库结构与实战参与指南6 CANN开源仓Catlass横模库适配自定义模型踩坑录7 昇腾CA

大规模训练集群性能问题(下降或抖动)分享及性能问题解决方案
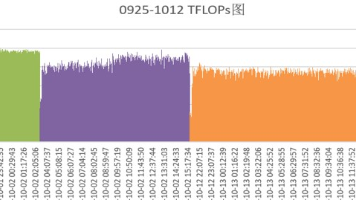
为了进一步挖掘 XTuner V1 训练方案的上限,实验室研究团队与华为昇腾技术团队在 Ascend A3 超节点上进行联合优化,充分利用超节点硬件特性,FSDP2首次在Qwen 235B MoE上实现了相比传统3D并行更高的 MFU(Model FLOPS Utilization,模型浮点运算利用率)。在理论算力落后 NVIDIA H800 近 20% 的情况下,最终实现训练吞吐超过 H800