




- @daihaoguang
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在上一篇,我们解读了《Fast Transformer Decoding: One Write-Head is All You Need》这篇文章,确认了MHA在Decode阶段的问题,分析了MQA方法带来的优化。具体来说,MQA的KV Cache压缩成了原来1hh1hhh为注意力头的个数),增加了计算强度,缓解了问题;同时,KV Cache的减少意味着可以增加batch size,也即可以同时

上一篇我们对工作《Fast Inference from Transformers via Speculative Decoding》进行了讲解,对大模型推理加速范式有了基本的认识。尽管上述工作设计简洁,但在实际场景中有如下问题需要克服:1)需要额外训练一个,且尽可能保持其输出分布与一致;2)将一同集成到分布式系统中具有挑战性。对于1)补充说明一下:尽管开源模型系列通常包含不同尺寸的模型,且它们的
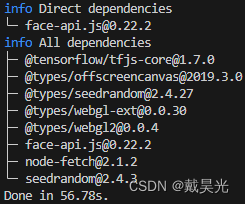
项目要求实现web端的人脸比对,即对比两张图片中的人脸是否为同一个人。此问题可以通过人脸识别相关模型来实现,比如经典的FaceNet。然而,图片中通常不止包含人脸,为了更好的提取人脸嵌入向量,就需要先借助人脸检测算法(如RetinaFaceMTCNN)抠出人脸部分;其次,实践发现人脸倾斜对最终的效果有较大的影响,因此还需要关键点检测算法对人脸进行对齐操作。简言之,整体流程为:1)人脸检测,2)关键
OCR,光学字符识别)是指对包含文本内容的图像或视频进行处理和识别,并提取其中所包含的的文字及排版信息的过程(摘自维基百科)。根据其应用场景可分为印刷文本识别、手写文本识别、公式文本识别、场景文本识别以及古籍文本识别。举一个实用的例子:想阅读一本电子书,但该书是扫描版的 PDF 文档,具有文件体积大、文字不可选、无法编辑和可读性差的缺点;我们可以借助OCR将文档识别并转换成轻量的 EPUB 格式,

vllm是一个优秀的大模型推理框架,它具备如下优点:易于使用,且具有最先进的服务吞吐量、高效的注意力键值内存管理(通过实现)、连续批处理输入请求、优化的CUDA内核等功能(摘自qwen使用手册为了深刻的理解vllm,我将写系列文章来解析,内容包括:1)小试牛刀,使用vllm来推理和部署一种大模型;2)深入理解,源码解析。因为Qwen2在同期的大模型中效果确实不错,并且有相应的使用手册(前面已给出)

项目要求实现web端的人脸比对,即对比两张图片中的人脸是否为同一个人。此问题可以通过人脸识别相关模型来实现,比如经典的FaceNet。然而,图片中通常不止包含人脸,为了更好的提取人脸嵌入向量,就需要先借助人脸检测算法(如RetinaFaceMTCNN)抠出人脸部分;其次,实践发现人脸倾斜对最终的效果有较大的影响,因此还需要关键点检测算法对人脸进行对齐操作。简言之,整体流程为:1)人脸检测,2)关键