




- @chenxuegui123
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1、性能无论是分布式系统还是单机系统,都会对性能(performance)有所要求。对于不同的系统,不同的服务,关注的性能不尽相同、甚至相互矛盾。常见的性能指标有:系统的吞吐能力,指系统在某一时间可以处理的数据总量,通常可以用系统每秒处理的总的数据量来衡量;系统的响应延迟,指系统完成某一功能需要使用的时间;系统的并发能力,指系统可以同时完成某一功能的能力,通常也用 QPS(query per ..
由于由近几年微服务架构兴起,领域驱动设计也被大多领域专家重新看待。但是其实这其实本来是不想关的两个东西,领域驱动设计更加强调的是一个架构设计理念,所谓理念的东西,就像是建议你怎么做,但不会对,而微服务着重在架构设计由于DDD设计的理念偏广,DDD名词概念,DDD与微服务落地,DDD事件风暴及领域建模,DDD大中台实践,DDD与领域模型一致性等等话题,笔者这里就DDD分层架构展开编写,当然...

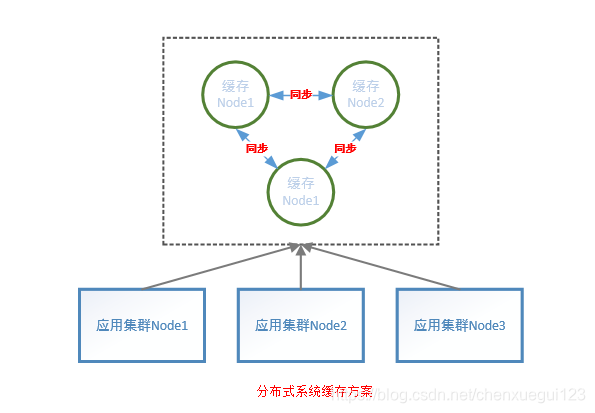
概述分布式系统经常会采用缓存提高系统吞吐量,从缓存存储的方案,缓存分为本地缓存和分布式中间件缓存(redis、memcached等)。对于分布式中间件缓存的节点同步其实还是很好处理的,应用服务器集群都是向中间件缓存操作缓存数据,只需要保证缓存中间件节点的数据一致性即可保证缓存数据一致性。当然,对于不同的缓存中间件,节点数据同步机制也处理方案也会有所不同,衍生了一系列解决方案:一致性hash、数..
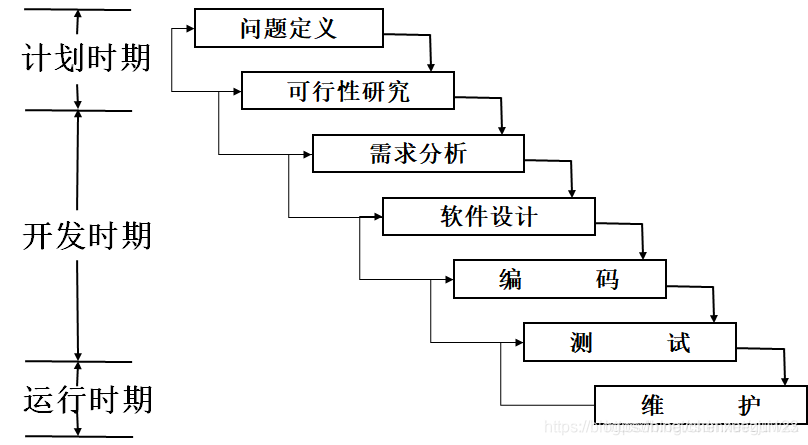
原文大部分内容来自https://blog.csdn.net/zjuwxx/article/details/97252039(感谢博主)同时加入了第5点 喷泉模型一 瀑布模型1.1 什么是瀑布模型1970年温斯顿.罗伊斯提出了著名的“瀑布模型”,直到80年代早期,它一直是唯一被广泛采用的软件开发模型瀑布模型将软件生...
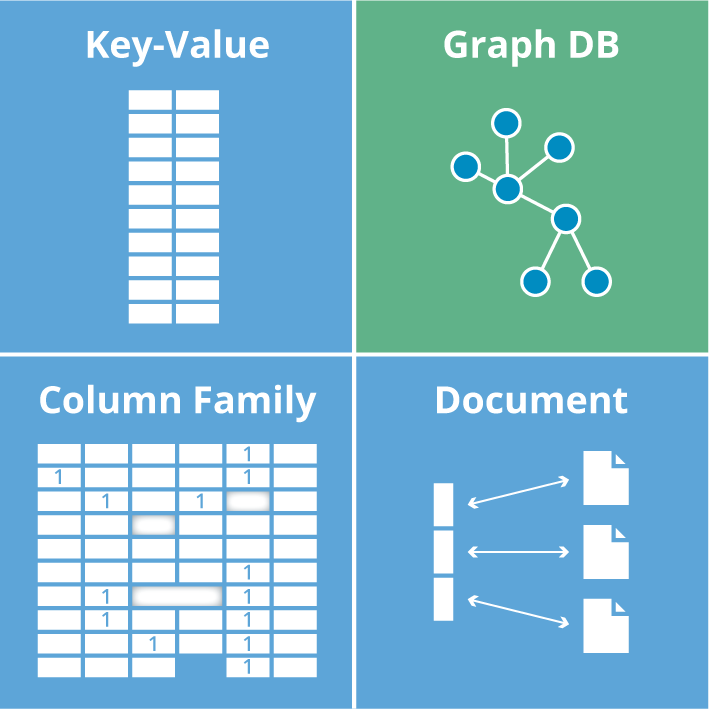
随着社交、电商、金融、零售、物联网等行业的快速发展,现实社会织起了了一张庞大而复杂的关系网,传统数据库很难处理关系运算。大数据行业需要处理的数据之间的关系随数据量呈几何级数增长,亟需一种支持海量复杂数据关系运算的数据库,图数据库应运而生。世界上很多著名的公司都在使用图数据库。比如:社交领域:Facebook, Twitter,Linkedin用它来管理社交关系,实现好友推荐零售领域...
Maven只单独部署某个pom,比如只deploy父pom,不deploy子模块实例如果原来工程maven结构pgroup:partifact:1.0.0-RELEASEpgroup:module1:1.0.0-RELEASEpgroup:module2:1.0.0-RELEASEpgroup:module3:1.0.0-RELEASE升级module3...
双重哈希是开放寻址哈希表中的冲突解决技术。双重哈希的思想是在发生冲突时对键做第二个哈希函数。双重哈希可以处理:(hash1(key) + i * hash2(key)) % TABLE_SIZE这里 hash1() 、 hash2() 是hash 函数,TABLE_SIZE 是hash表大小(如果发生冲突,i递增然后重复运算)通俗的二次Hash函数:hash2(key) ...

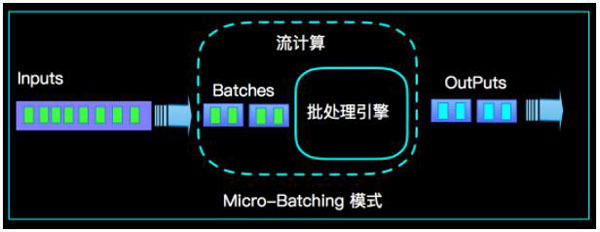
最近也是有很多同学问我spark和flink到底谁好,应该怎么选择,这也是近年来被问的最多的问题,也是经常被拿来比较的,今天就简单的做一个对比,我没有要挑起spark和flink之间的战争,社区间取长补短也好,互相抄袭也罢,我尽量站在一个公平的角度对待他们.下面会从多个方面对两者进行分析(当然有不全面),希望对大家有所帮助.篇幅较长,望大家耐心阅读.Spark简介Spark的历史比较悠久,...
说明:在ABCD中加黑的部分为正确答案。1. cron 后台常驻程序 (daemon) 用于:A. 负责文件在网络中的共享B.管理打印子系统C. 跟踪管理系统信息和错误D. 管理系统日常任务的调度2.在大多数Linux发行版本中,以下哪个属于块设备 (block devices) ?A. 串行口B. 硬盘C. 虚拟终端D. 打印机3.下面哪个Linux命令可...

如果你是Spring新手的话,可以去http://download.csdn.net/detail/chenxuegui123/6881245下一些源代码例子跟着调试运行因为WebApplicationContext 需要ServletContext 实例,也就是说它必须在拥有Web 容器的前提下才能完成启动的工作。有过Web 开发经验的读者都知道可以在web.xml 中配置自启动的Servlet