




- @chaojichaoachao
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
总结灵长类动物识别例如人脸的复杂目标有着难以置信的速度和准确度。这里,我们揭示了人脸识别的大脑编码。猕猴的实验描述了一个人脸和人脸块胞元响应之间的转换。通过将人脸在高维空间形成点,我们发现每一个人脸胞元的发射率正比于即将到来的人脸刺激在这个空间单个坐标轴上的投影,这就允许人脸胞元的集合编码空间中任意脸的位置。用这个编码,我们能精确地从神经入口响应中编码人脸以及预测神经对人脸的发射率。此外,这个编码
深度神经网络的不确定度摘要深度神经网络的不确定度A.数据获取B.深度神经网络设计与训练欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注脚注释也是必不可少的KaTeX数学公式新的甘特图功能,丰富你的文章U
在我们所讨论的三度空间(三维)中,能够出现的微分形式只有四种:零次微分形式——函数 f一次微分形式——线积分中出现的微分dx,dy,dz的一次式二次微分形式——面积分中出现的微分dx,dy,dz的二次式三次微分形式——体积分中出现的微分dx,dy,dz的三次式...
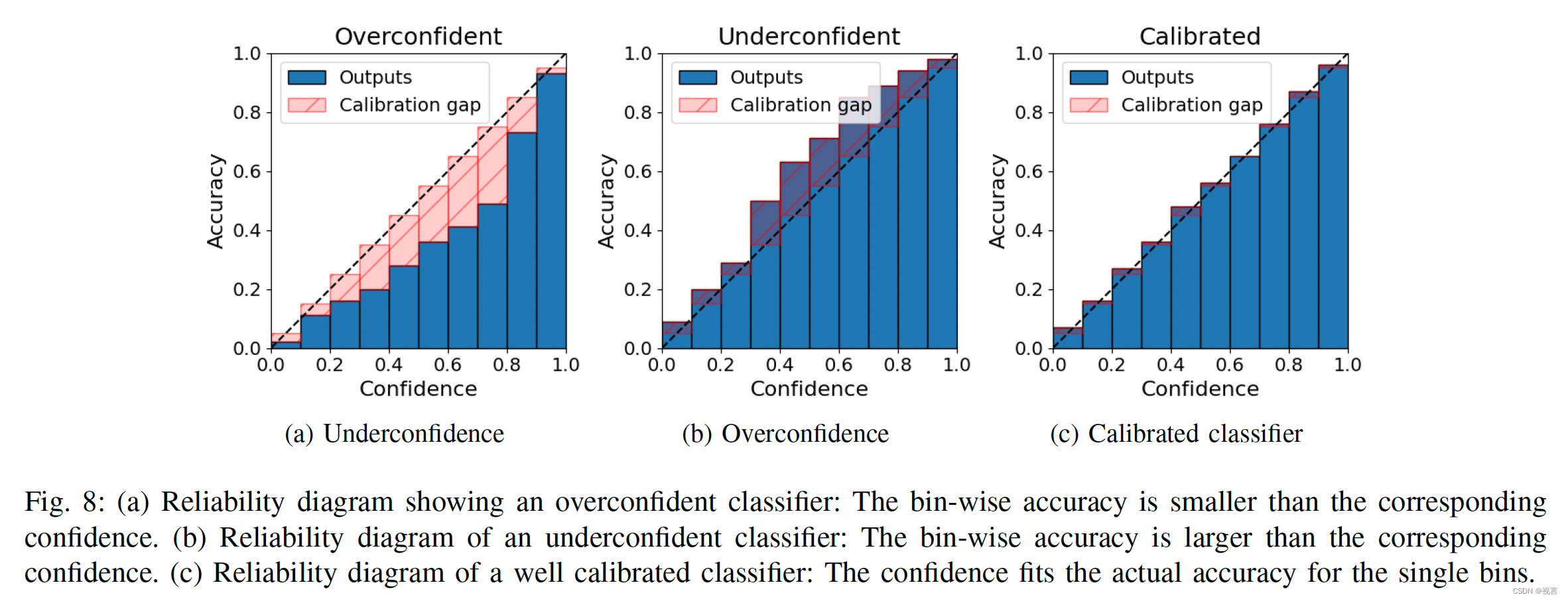
目录不确定性的测量和定性估计分类任务中的不确定性测量分类任务中的数据不确定性测量分类任务中的模型不确定性测量分类任务中的分布不确定性完备数据集性能测量估计回归任务中的不确定性测量回归任务中的数据不确定性测量回归任务中的模型不确定性估计回分割任务中的不确定性校准校准方法正则化方法后处理方法不确定性估计校准方法估计校准质量数据集与baseline不确定性估计的应用总结不确定性的测量和定性顾名思义,我们
目录不确定度估计方法A.Single Deterministic MethodsB.Bayesian Neural NetworksC. Ensemble MethodsD. Test Time AugmentationE. Neural Network Uncertainty Quantification Approaches for Real Life Applications不确定度估计方法