




- @bylander
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
VSCode中就可以安装,点击两下,非常容易就完成了安装
ReAct 通过交错推理与行动,首次在统一框架中实现了 LLM 的“边想边做”,在知识推理与交互决策任务中均取得显著性能与可解释性提升,为构建更智能、可控、可扩展的语言智能体开辟了新路径。

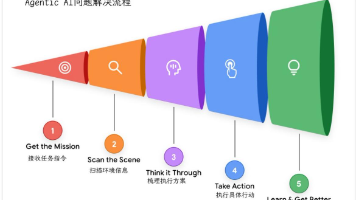
用最通俗的话来说,AI智能体可以定义为模型、工具、编排层和运行时服务的组合体——它通过让大语言模型(LM)在循环中持续工作,最终实现既定目标。这四个要素共同构成了任何自主系统的核心架构:模型(“大脑”):作为智能体核心推理引擎的大语言模型或基础模型,负责处理信息、评估选项并做出决策。模型的类型(通用型、微调型或多模态型)决定了智能体的“认知能力”水平。一个Agentic AI系统,本质上是大语言模
摘要: markdown.new是一款免费网页转Markdown工具,可自动去除广告和冗余样式,保留核心内容,使网页体积减少80%。支持三种使用方式:浏览器地址前加markdown.new/、API调用或开源部署。采用三层转换机制确保稳定性,每日限500次请求。测试案例显示其成功将技术文章转换为结构化Markdown,保留了标题、列表和链接等要素。该工具特别适合需要处理网页内容的AI应用,能有效降

李宏毅新课《DeepSeek-R1 这类大语言模型是如何进行「深度思考」(Reasoning)的?》的部分纪要

使用结构化状态空间序列(S4)层的模型在长距离序列建模任务中取得了最先进的性能。S4层结合了线性状态空间模型(SSM)、HiPPO框架和深度学习来实现高性能。我们以S4层的设计为基础,引入了一个新的状态空间层,即S5层。S4层使用许多独立的单输入、单输出SSM,而S5层使用一个多输入、多输出SSM。我们在S5和S4之间建立了一个连接,并利用它来开发S5模型所使用的初始化和参数化。其结果是,状态空间

要有光。对于生物而言,要有光,原来不是有了光,而是,生物进化了视觉系统,能够看见光,有了光,进一步就有了理解,有了行动。原来如此!

人工智能发展史三根靠得住的基本支柱:一是神经网络,二是强化学习,三是环境模型。

华为5G-A+AI网络技术已在全国30余省份落地,覆盖高密场景、智慧文旅等领域。

关于WiFO论文中数据集的调研
