
写文章




- @bobchen1017
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
深度学习部署(十二): CUDA RunTime API 共享内存
学习共享变量共享内存

深度学习部署笔记(三): GPU架构解析 + CUDA编程基础
学习GPU架构以及通过一个小案例来了解CUDA编程的基础grid block
深度学习部署笔记(八): CUDA RunTime API-2.1Hello CUDA
通过对比CUDA-Driver API 和 Runtime API理解懒加载的含义,不用cuInit, 不用destory,自动使用创建上下文cuDevicePrimaryCtxRetain并设置当前context
深度学习部署笔记(三): GPU架构解析 + CUDA编程基础
学习GPU架构以及通过一个小案例来了解CUDA编程的基础grid block
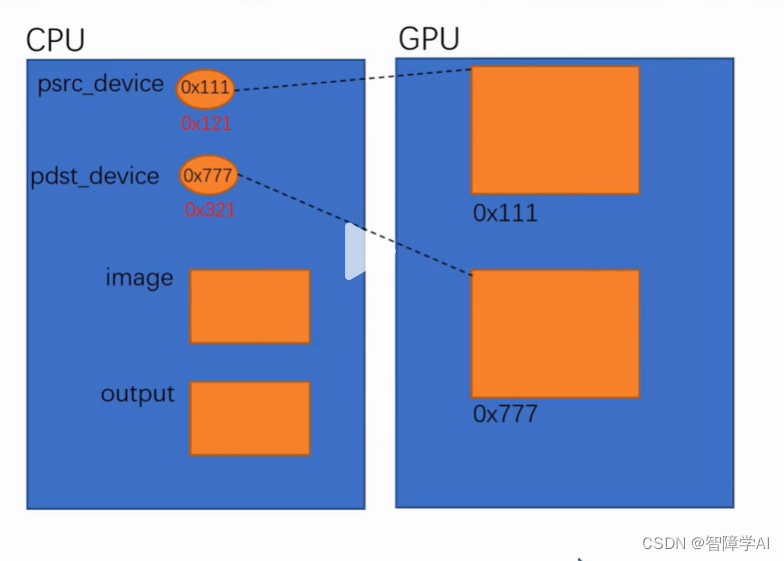
深度学习部署(十八): CUDA RunTime API _wa_仿射变换的实现
warpAffine是一种二维仿射变换技术,可以将图像从一种形式转换为另一种形式。它是OpenCV图像处理库中的一个函数,可用于对图像进行平移、旋转、缩放和剪切等操作。仿射变换可以通过线性变换来描述,可以用一个2x3的矩阵来表示。在图像处理中,这个矩阵通常称为变换矩阵,其中包含了平移、旋转、缩放和剪切的参数。通过warpAffine函数,我们可以将这个变换矩阵应用到输入图像中的每个像素上,从而生成
深度学习基础: BP神经网络训练MNIST数据集
BP 神经网络训练MNIST数据集
深度学习基础: BP神经网络训练MNIST数据集
BP 神经网络训练MNIST数据集
