




- @binbinxyz
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
题目在屏幕上打印出n行的金字塔图案,如,若n=5,则图案如下:*************************代码package org.hbin.example;import java.util.Scanner;public class PyramidTest {private static final Scanner scan = new Scanner(System.in);public
堆排序(Heap Sort)是一种基于二叉堆数据结构的比较排序算法。它利用了完全二叉树的特性,将待排序的数据构造成一个最大堆或最小堆,然后通过不断移除堆顶元素并重新调整堆来实现排序。堆排序具有稳定的时间复杂度O(n log n),并且不需要额外的空间,因此在处理大规模数据时表现良好。堆排序作为一种经典的排序算法,不仅在理论上有重要的意义,在实际应用中也经常被使用。理解堆排序的工作原理及其背后的二叉

归并排序是一种非常高效的排序算法,特别适合处理大规模数据集。尽管它的空间复杂度较高,但由于其稳定性和一致的时间复杂度,使其成为许多实际应用中的首选排序算法之一。

通过本文的指导,你现在应该能够轻松地在 IntelliJ IDEA 中安装并使用 BinEd 插件。这将大大提高你在查看和分析二进制文件时的工作效率。

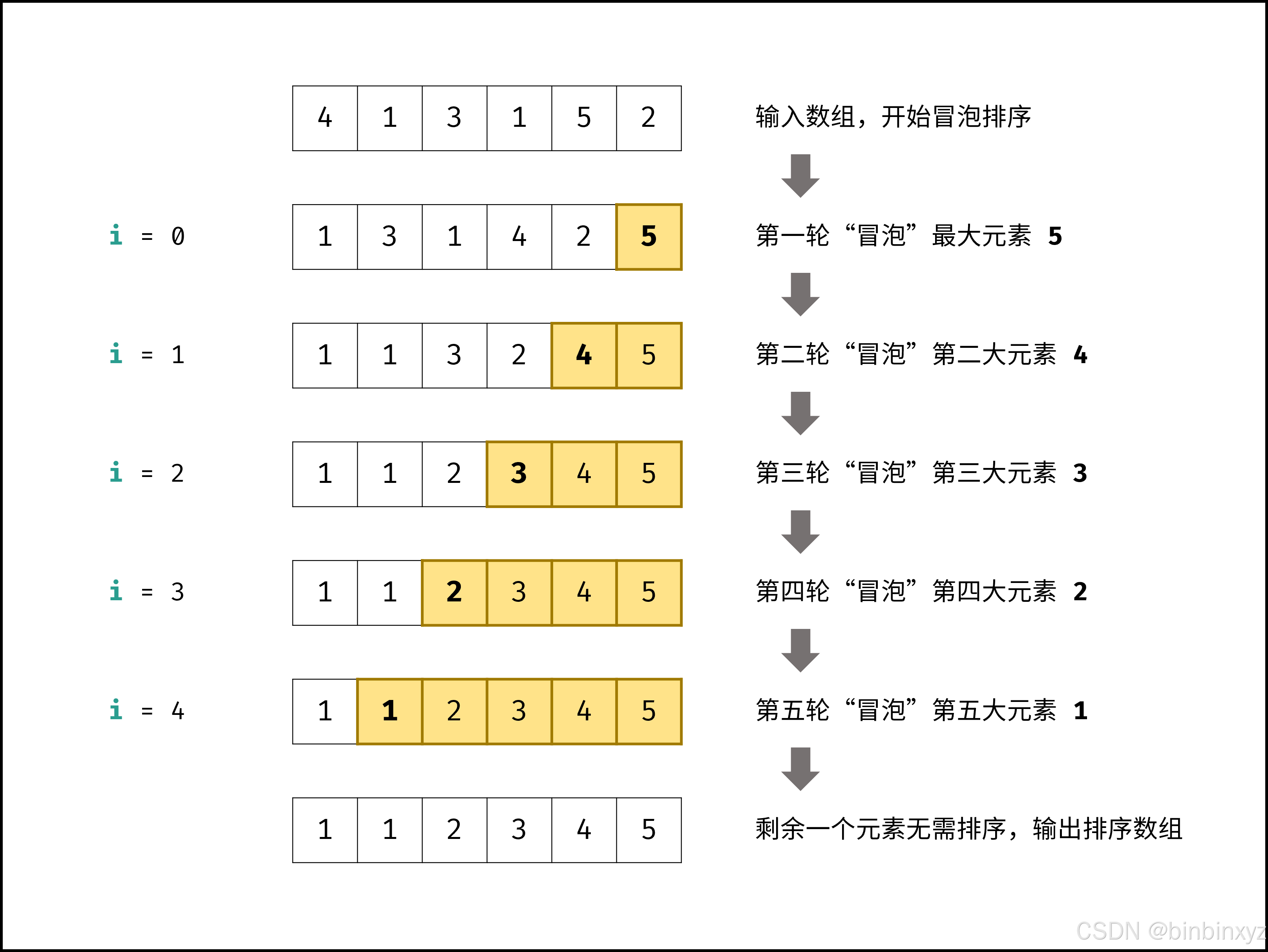
排序算法时间复杂度(最好)时间复杂度(平均)时间复杂度(最坏)空间复杂度稳定性冒泡排序O(n)O(n^2)O(n^2)O(1)稳定选择排序O(n^2)O(n^2)O(n^2)O(1)不稳定插入排序O(n)O(n^2)O(n^2)O(1)稳定。
基数排序(Radix Sort)是一种非比较型整数排序算法,它通过逐位处理数字来实现排序。与快速排序、归并排序等基于比较的排序算法不同,基数排序利用了每个数字的位值进行排序,因此可以在O(n)的时间复杂度内完成排序任务。基数排序适用于对正整数、负整数以及固定长度的字符串进行排序。基数是指数字系统中的基本单位或基础值。它决定了一个数位上可能有多少种不同的符号或数值。例如,在十进制系统中,基数是10,

如果默认配置不能满足你的需求,你可以创建一个自定义的 Druid 配置类来覆盖默认设置。@Bean// 如果需要,可以在这里添加更多配置,如过滤器、拦截器等@Bean@Bean通过以上步骤,我们成功地在 Spring Boot 应用中集成了 Druid 数据库连接池,并开启了其监控功能。这不仅提高了数据库访问的效率,还为开发者提供了宝贵的调试和优化工具。希望这篇文章能够帮助你。

Java虚拟机规范的描述中,除了程序计数器外,虚拟机内存的几个运行时区域都可能发生OutOfMemoryError(OOM)。

使用NAT模式,就是让虚拟系统借助NAT(网络地址转换)功能,不需要你进行任何其他的配置,只需要宿主机器能访问互联网,虚拟机系统通过宿主机器所在的网络来访问公网。使用桥接模式的虚拟系统和宿主机器的关系,就像连接在同一个Hub上的两台电脑。想让它们相互通讯,你就需要为虚拟系统配置IP地址和子网掩码,否则就无法通信。
担心创建的虚拟机硬盘容量太大会占用真正的硬盘空间,把硬盘的容量设置得很小,可是等到给虚拟机装好系统后再装其他的软件,才发现硬盘容量不够用了。这就需要想办法扩展Ubuntu根分区,下面我来介绍这样一种方法。