




- @baishuiniyaonulia
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
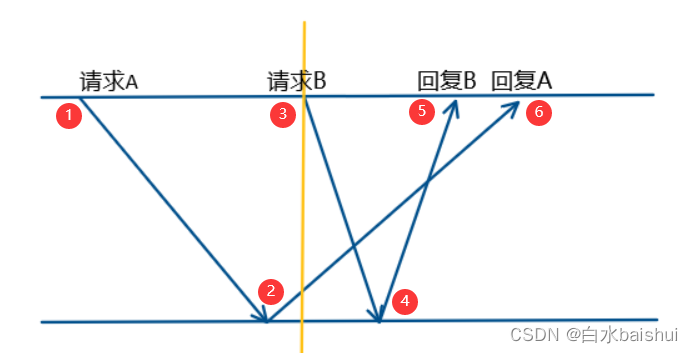
1. 分布式互斥算法的概念分布式互斥算法,就是在分布式系统中,通过某种消息传递算法来决定,控制哪个进程可以访问临界区资源。如何去评价分布式互斥算法是否达到了这个目的呢?于是就定义出了三个算法指标:ME1 安全性至多一个进程在使用临界区,不会有多个进程同时在临界区执行;ME2 活性不会发生死锁、饿死现象;ME3 公平性进程顺序执行(FIFO),先到先进。能满足这三个条件的算法,就是一个良好的分布式互
Series是DataFrame的一个子结构,把DataFrame中的某一列或者某几列单独拿出来就是一个Series结构,相当于Numpy当中ndarray导入pandas库import pandas as pd我们以一个csv文件来演示Series的作用:fandango_score_comparison.csv导入csv文件fandango_score_comparisio...
基于区域的分割是以直接寻找区域为基础的分割技术,实际上类似基于边界的图像分割技术一样利用了对象与背景灰度分布的相似性。大体上基于区域的图像分割方法可以分为两大类:区域生长法区域分裂与合并1 区域生长法根据一定的准则将像素或子区域聚合城更大区域的过程。区域生长法的关键在于选取合适的生长准则,不同的生长准则会影响区域生长的过程、结果。生长准则可根据不同的原则制定,大部分区域生长准则使用图...
导入pandas库和numpy库import pandas as pdimport numpy as np我们以一个csv文件来展示pandas是如何来进行数据预处理的:titanic_train.csv读入文件titanic_train.csvtitanic_survival = pd.read_csv("titanic_train.csv")1、求平均值①通过...
导入pandas库和numpy库import pandas as pdimport numpy as np我们以一个csv文件来展示pandas是如何来进行数据预处理的:titanic_train.csv读入文件titanic_train.csvtitanic_survival = pd.read_csv("titanic_train.csv")1、求平均值①通过...
导入pandas库和numpy库import pandas as pdimport numpy as np我们以一个csv文件来展示pandas是如何来进行数据预处理的:titanic_train.csv读入文件titanic_train.csv,并显示前十行数据titanic_survival = pd.read_csv("titanic_train.csv")tit...
《强化学习推荐系统中的汤普森采样探索策略》介绍了推荐系统中强化学习的探索策略,重点阐述了汤普森采样方法。汤普森采样通过贝叶斯推断估计每个动作的最优概率,利用Beta分布作为先验分布,结合观测数据更新后验分布。该方法能有效平衡探索与利用,适用于二值奖励场景,通过参数调整动态优化策略。文章包含数学推导和Python实现代码,展示了该策略在5臂赌博机问题中的应用。
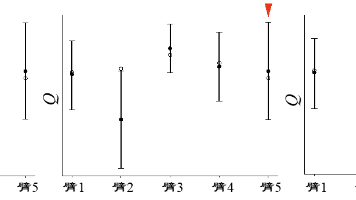
本文介绍了强化学习中UCB探索策略在多臂机问题中的应用。UCB策略通过置信上界公式Q_t(a)+c√(log t/N_t(a))平衡探索与利用,其中c为超参数,t为时间步。该策略在初始阶段优先探索不确定性较大的臂,随着试验次数增加逐渐收敛于真实期望值。文中提供了Python实现代码,并展示三阶段探索过程示例,说明UCB如何动态调整臂的选择。相比单纯均值估计,UCB策略能更快收敛且保证遗憾值呈对数增
Series是DataFrame的一个子结构,把DataFrame中的某一列或者某几列单独拿出来就是一个Series结构,相当于Numpy当中ndarray导入pandas库import pandas as pd我们以一个csv文件来演示Series的作用:fandango_score_comparison.csv导入csv文件fandango_score_comparisio...
在pytorch中,保存神经网络用方法:torch.save(net, 'net.pkl')提取神经网络用方法:torch.load('net.pkl')保存神经网络有两种方式:1、保存整个网络torch.save(net, 'net.pkl')这种方法能最大程度的保留网络的所有信息,缺点是读取网络时速度稍慢2、保存网络的状态信息torch.save(net.state_d...