




- @asterfusion
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
gRPC(Google Remote Procedure Call) 是一个高性能、开源且与语言无关的远程过程调用(RPC)框架,最初由 Google 开发并基于 HTTP/2作为传输协议、Protocol Buffers(protobuf) 作为接口描述语言(IDL)和消息交换格式。若是采用基于gRPC + Protocol Buffers的运维接口设计,可以很好地满足运维对单个网络网元全面的可
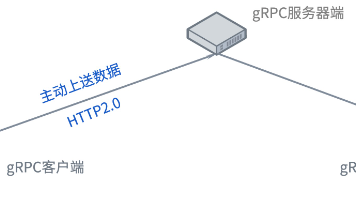
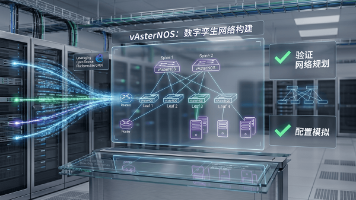
智算中心网络演进面临高风险?星融元推出了适用于星融元智算/云数据中心网络产品的数字孪生网络方案。实现零硬件成本组网验证,支持RoCEv2与REST API无缝集成。在真实物理网络部署和改造之前,预先验证网络规划和交换机配置效果,从而提高创新效率,降低试错成本。
Asterfusion ET2508 搭配 OpenClaw,让 ARM64 智能网关实现 AI 驱动的自动化运维。从代理部署到编译 Snort 3,全程无需手动干预,释放本地算力潜力,迈向“智力自由”的边缘网络中枢。

VPP 这一开源技术在通用 CPU 的基础上,实现了传统上需要专门的网络硬件设备(如路由器)和专业的网络操作系统才能达到的性能,以极高的性价比为广大用户带来了开放网络技术的红利。VPP 集成了DPDK项目,通过它直接访问硬件网卡资源。
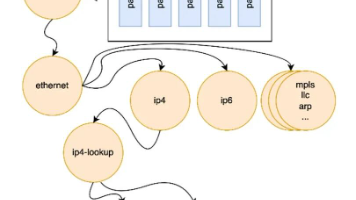
P4语言的编译器设计体现了模块化思想,各个模块通过标准化配置文件进行信息交换。这种设计赋予了P4语言三大关键特性:协议无关性、目标无关性和可重构性。它允许用户自定义数据平面的报文处理逻辑,提高了数据平面的可编程性,使得网络设备能够灵活地支持各种新兴的协议和功能。
数据库一体机通常采用X86服务器和InfiniBand网络的硬件环境,现在,RoCE网络可以提供与InfiniBand网络相当的性能。因此使用RoCE网络替代InfiniBand网络,可以降低成本、提高组网的灵活性和可扩展性,更容易地进行部署和运维

EasyRoCE-CMA 是基于 INT 技术的拥塞监控工具 。它利用纳秒级精度的 HDC 与 BDC 捕获信息 ,实现交换机端口级拥塞与丢包的一站式可视化 。该工具能精准定位故障根因,辅助 AI 智算网络快速调优 。

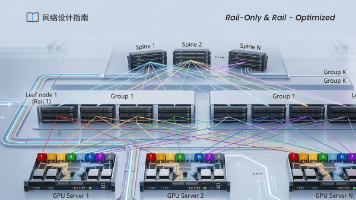
大模型时代AI智算网络如何决定GPU训练效率?本文深度解析智算网络四大平面、无损网络核心技术及万卡集群落地部署方案,助您释放极致算力。
VPP 这一开源技术在通用 CPU 的基础上,实现了传统上需要专门的网络硬件设备(如路由器)和专业的网络操作系统才能达到的性能,以极高的性价比为广大用户带来了开放网络技术的红利。VPP 集成了DPDK项目,通过它直接访问硬件网卡资源。
近年来,千亿至万亿参数规模的大语言模型(LLM)训练已成为人工智能领域的核心战场。随着模型复杂度的指数级增长, 并行计算与网络拓扑的协同设计逐渐成为突破算力瓶颈的关键挑战。在,全局梯度同步(All-Reduce)对网络带宽提出严苛要求。早期的CLOS架构凭借无阻塞特性支撑了大规模集群的扩展,但其高昂的硬件成本与能效问题催生了Dragonfly等低直径拓扑的兴起,通过自适应路由减少跨节点跳数。与此同
