- @aidoudoulong
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2026 年的文生视频赛道在四个月内连续经历三次格局重写:4 月阿里巴巴以 HappyHorse 1.0 匿名登顶 Artificial Analysis Video Arena,5 月 Google 在 I/O 大会上发布 Gemini Omni 把视频编辑变成对话,6 月快手可灵 3.0 以最低 API 单价正面竞争,7 月字节跳动 Seedance 2.5 把单次生成时长推到 30 秒。本文
摘要: Anthropic发布MCP(模型上下文协议)2026-07-28版本,这是其开源后最大规模更新,核心变革包括转向无状态架构、标准化三大扩展功能及强化安全体系。MCP生态爆发式增长,月SDK下载量达4亿,TypeScript/Python SDK累计下载超10亿次。新版本支持Serverless部署、负载均衡优化,并引入交互式UI(MCP Apps)、异步任务处理(Tasks)和企业级认证
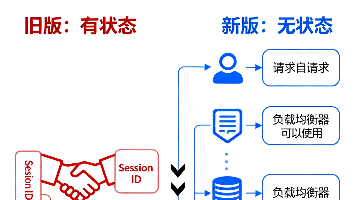
摘要: Anthropic发布MCP(模型上下文协议)2026-07-28版本,这是其开源后最大规模更新,核心变革包括转向无状态架构、标准化三大扩展功能及强化安全体系。MCP生态爆发式增长,月SDK下载量达4亿,TypeScript/Python SDK累计下载超10亿次。新版本支持Serverless部署、负载均衡优化,并引入交互式UI(MCP Apps)、异步任务处理(Tasks)和企业级认证
摘要: Anthropic发布MCP(模型上下文协议)2026-07-28版本,这是其开源后最大规模更新,核心变革包括转向无状态架构、标准化三大扩展功能及强化安全体系。MCP生态爆发式增长,月SDK下载量达4亿,TypeScript/Python SDK累计下载超10亿次。新版本支持Serverless部署、负载均衡优化,并引入交互式UI(MCP Apps)、异步任务处理(Tasks)和企业级认证
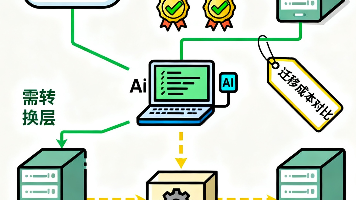
Codex上下文迁移三大场景操作指南 摘要:Codex的上下文迁移功能涵盖三类场景:1)工具迁移(从Claude Code/Cursor导入配置和历史);2)跨会话延续(通过AGENTS.md和Memories系统保持项目规则与偏好);3)长任务管理(利用自动压缩和PreCompact Hook防止上下文溢出)。文章提供了详细操作步骤:工具迁移支持一键导入或手动配置;跨会话依赖AGENTS.md存

xAI将于2026年8月7日前发布新一代大语言模型Grok 4.6,参数规模从4.5代的1.5万亿提升至2万亿,依托Colossus超级计算集群训练完成。马斯克表示其性能全面超越前代,同时保持相近的推理效率。该模型将直面月之暗面2.8T参数的Kimi K3等竞品的挑战。值得注意的是,xAI正以每月一款的速度迭代模型,4.7版预计8月21日前推出。Grok系列凭借高参数、低价格和快迭代的策略,在代码
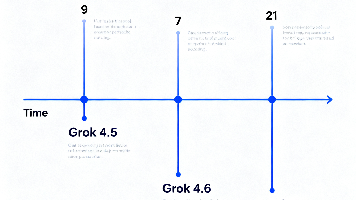
xAI将于2026年8月7日前发布新一代大语言模型Grok 4.6,参数规模从4.5代的1.5万亿提升至2万亿,依托Colossus超级计算集群训练完成。马斯克表示其性能全面超越前代,同时保持相近的推理效率。该模型将直面月之暗面2.8T参数的Kimi K3等竞品的挑战。值得注意的是,xAI正以每月一款的速度迭代模型,4.7版预计8月21日前推出。Grok系列凭借高参数、低价格和快迭代的策略,在代码
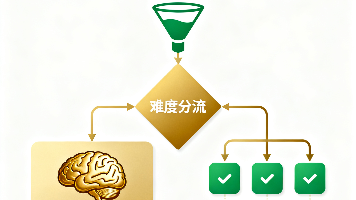
GLM-5.2 以 39% 的价格保留 96% 的指数能力,是最小损失之选;DeepSeek V4 Flash 以 2.6% 的价格覆盖简单任务,是数量级省钱之选;Gemini 3.5 Flash 和 Kimi K2.7 Code 分别在生态与纯代码场景占位。最优解不是找到"那一个"平替,而是搭好难度路由——让 Sonnet 5 只处理配得上它价格的任务。据 Artificial Analysis
先定模型再定平台(重度绑定某家自研模型就去它主场拿补贴价);模型未定先上聚合(七牛云/硅基流动一个 Key 试遍主流,七牛云的同屏对比和 Anthropic 兼容对 AI 编程用户尤其顺手);企业交付看配套(编排、观测、合规上千帆和方舟投入最重)。免费额度是真实的试错预算——百炼 7000 万和七牛云 300 万足够完成一轮认真的选型评测,先测后买永远是最优策略。据六家平台官方页面(2026 年
GPT-5.6 Sol 首批内测的核心结论清晰:它以约为 Fable 5 一半的成本(5 美元 / 30 美元 vs 10 美元 / 50 美元),交出了代码更简洁、更盯底层性能优化的表现,英伟达工程师实测其 CUDA 加速 30 小时跑赢 Opus 64 小时的效果。代价是迭代较慢、失败较多、探索灵活性不足。对比来看,Sol 强在成本与代码简洁,Fable 5 强在整体体验与成品完成度,二者胜负