- @ab977a1081268482
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
OpenAI 于 2026 年 7 月 9 日正式推出 GPT-5.6 系列——旗舰 Sol、均衡 Terra、性价比 Luna;独立评测 Artificial Analysis 智能指数约 59 / 55 / 51,Sol 紧贴 Claude Fable 5;Coding Index 约 77.4 居首,Agentic Index 约 54 居首;Arena Agent 盲测第 2、WebDev
月之暗面于2026年7月16日发布旗舰模型Kimi K3,参数规模达2.8万亿,支持100万tokens长上下文及原生多模态(图像/视频理解)。独立评测显示其综合能力位列第三,紧追Claude Fable 5与GPT-5.6 Sol,并在Arena前端盲测榜登顶(1679分)。K3擅长长程编程、办公Agent及创作任务,API定价为缓存命中¥2/百万tokens,未命中¥20,输出¥100。完整权
月之暗面于2026年7月16日发布旗舰模型Kimi K3,参数规模达2.8万亿,支持100万tokens长上下文及原生多模态(图像/视频理解)。独立评测显示其综合能力位列第三,紧追Claude Fable 5与GPT-5.6 Sol,并在Arena前端盲测榜登顶(1679分)。K3擅长长程编程、办公Agent及创作任务,API定价为缓存命中¥2/百万tokens,未命中¥20,输出¥100。完整权
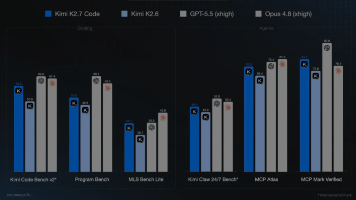
摘要 月之暗面于2026年6月12日发布并开源编程专用模型Kimi K2.7 Code,6月15日上线高速推理版本。该模型基于K2.6架构,专注于编程任务优化,采用MoE结构(1T总参/32B激活),支持256K上下文和图像/视频输入。官方测试显示,相比K2.6,其在编程基准上提升11-31.5%,思考token减少30%,但通用任务表现可能下降。社区实测表明K2.7在代码审查中更精准简洁,但响应
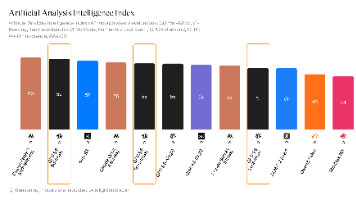
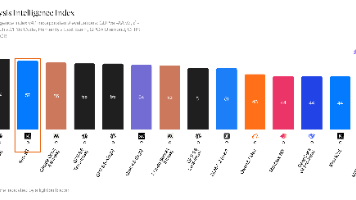
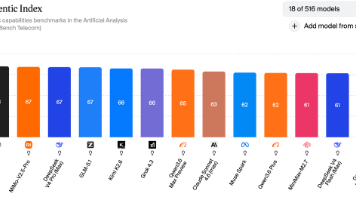
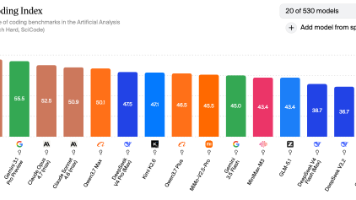
基于独立评测机构Artificial Analysis发布的最新AI模型基准测试结果,本文围绕Agentic智能指数与Coding Agent指数两大核心维度展开横向对比。这两项指标与日常代码开发需求和OpenClaw、Harness等通用Agent场景高度契合:Agentic能力直接决定模型自主规划复杂任务、调度外部工具、驱动自动化流程的水平Coding Agent能力则是评估模型代码生成、调试
摘要 月之暗面于2026年6月12日发布并开源编程专用模型Kimi K2.7 Code,6月15日上线高速推理版本。该模型基于K2.6架构,专注于编程任务优化,采用MoE结构(1T总参/32B激活),支持256K上下文和图像/视频输入。官方测试显示,相比K2.6,其在编程基准上提升11-31.5%,思考token减少30%,但通用任务表现可能下降。社区实测表明K2.7在代码审查中更精准简洁,但响应
GPT-5.5继续稳居 Coding 指数榜首,与 GPT-5.4、Claude Opus 4.8 共同构成第一梯队在 Agentic 智能指数登顶,成为 Agentic 新王跻身全球 Coding 指数前十(第七),是国产 AI 编程能力之巅Agentic 智能指数跻身全球第四以缓存命中 ¥0.02/百万 token 创下极低单价MiniMax-M3Agentic 智能指数跻身全球第五,国产阵营
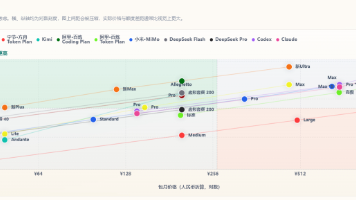
2026年6月底国内AI编程平台动态显示,头部厂商策略分化明显。智谱AI全面升级GLM-5.2模型但维持抢购机制,Kimi完成K2.7-Code版本迭代,字节方舟推出2.5折促销却同步收紧限购。当前市场呈现三大趋势:1)高质量模型向GLM-5.2和Kimi-K2.7集中;2)平台在促销力度与库存管控间反复平衡;3)Token计费方案透明度提升但实际扣减规则差异显著。建议开发者重点关注同价位可用量、
基于独立评测机构Artificial Analysis发布的最新AI模型基准测试结果,本文围绕Agentic智能指数与Coding Agent指数两大核心维度展开横向对比。这两项指标与日常代码开发需求和OpenClaw、Harness等通用Agent场景高度契合:Agentic能力直接决定模型自主规划复杂任务、调度外部工具、驱动自动化流程的水平Coding Agent能力则是评估模型代码生成、调试
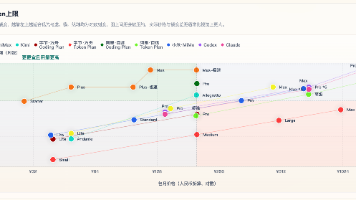
2026年5月主流AI编程平台对比分析报告摘要 报告显示,AI编程订阅市场正经历从传统Coding Plan向Token Plan的转型,头部厂商纷纷限购或取消Coding Plan。针对个人开发者,报告建议: 高频用户优先选择Coding Plan(按次计费、无Token上限),推荐智谱AI、MiniMax等平台;低频用户更适合直接调用API按量付费 对比25家主流平台套餐数据,Coding P