




- @a958014226
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2026 年 5 月 14 日,袋鼠云成功举办了以 “数字重构・智启新生” 为主题的春季数智发布会,系统阐述了面向 “十五五” 阶段国央企 Data+AI 一体化建设的方法论与落地实践。发布会上,袋鼠云解决方案专家红发带来了《迈向 “十五五” 数智新阶段:国央企基于 5A 架构的 Data+AI 一体化融合建设方案》专题演讲,深入解读了国央企如何在 “十五五” 背景与 AI 时代浪潮下,以新一代数

JavaAgent是一种在JVM启动时或运行时动态修改字节码的机制,广泛应用于APM监控、热部署等场景。本文介绍了两种Agent模式(Premain和Attach),并详细讲解了其核心原理:通过Instrumentation接口实现字节码转换。文章提供了完整的开发示例,包括创建Agent入口类、实现TraceAdvice、构建调用链上下文等步骤,最终通过两个Web应用验证了调用链跟踪功能。这种技术

袋鼠云作为长期深耕 “Data+AI”的领先数据智能与空间智能厂商,袋鼠云在DeepSeek-V3.1发布的第一时间完成了全栈产品适配,推动产品能力的整体升级。

2025年10月21日,袋鼠云以“数据筑基、智能跃迁”为主题,成功举办秋季发布会,详细介绍了多模态数据中台、空间智能引擎等一系列战略级产品与行业解决方案,全面呈现袋鼠云在“Data+AI”融合演进中的技术布局与产业实践,助力企业在智能时代构建自主可控、持续进化的数字竞争力!

摘要:本文介绍了AIWorks平台中Workflow引擎的设计与实现,旨在解决LLM应用开发中的Prompt失控、结果不可预测等问题。引擎采用DAG为骨架、状态机为灵魂的设计理念,通过节点系统实现能力扩展,并强调可观测性优先。架构分为应用层、图引擎层、节点层和基础设施层,GraphEngine作为核心调度器负责解析JSON、编译执行图并管理状态。节点系统采用模板方法模式,支持多种节点类型并易于扩展

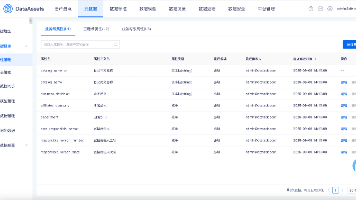
数据资产五层架构(L1-L5)是一种从业务到技术的分层建模方法,旨在解决企业数据管理中的孤岛、口径不一等问题。L1业务域(战略视角)划分企业核心领域;L2主题域(业务视角)细分业务流程;L3业务对象(概念视角)抽象核心业务概念;L4逻辑实体(设计视角)实现规范化数据结构;L5属性(实现视角)定义具体字段标准。该架构通过袋鼠云平台实现层级管理、属性自定义和审计跟踪,统一业务与技术语言,降低复杂度,提
某大型央企是首批全国供应链创新与应用示范企业,在“十四五”规划期内以聚焦供应链管理核心主业作为主要战略发展方向。供应链运营管理以大宗商品贸易为主,其交易往往具有交易量巨大、交易环节复杂、风险交易难识别、风险客商难管控等痛点。随着集团数字化转型不断深化,数据应用方面的需求不断扩展。但集团缺乏统一的,导致在数据应用方面,出现数据价值不凸显、数据标准不统一、数据质量不可控、数据共享不畅通等问题。在此背景
《AI赋能金融数字化转型:智能助手"灵瞳"的实践突破》摘要"十五五"规划推动"人工智能+"行动,金融领域AI应用已从辅助工具升级为核心竞争力。头部券商通过部署数栈智能助手"灵瞳",深度融合DeepSeek大模型能力,有效解决数据开发三大痛点:开发效率低(自然语言转SQL使查询效率提升至秒级)、运维成本高(智能诊断使异常排查缩短至分钟级)、平台门槛高(操作指引使新人上手周期缩短80%)。该实践覆盖数
2026 年 5 月 14 日,袋鼠云成功举办了以 “数字重构・智启新生” 为主题的春季数智发布会,系统阐述了面向 “十五五” 阶段国央企 Data+AI 一体化建设的方法论与落地实践。发布会上,袋鼠云解决方案专家红发带来了《迈向 “十五五” 数智新阶段:国央企基于 5A 架构的 Data+AI 一体化融合建设方案》专题演讲,深入解读了国央企如何在 “十五五” 背景与 AI 时代浪潮下,以新一代数
2026年,数字化早已不是可选项,智能化也不再是锦上添花。国家以“模数共振”行动自上而下推动产业升级,全模态大模型、AI Agent自下而上重构业务场景,中间的核心支点,就是多模态数据的治理与融合。企业需要尽快搭建能承接政策、能盘活数据、能支撑AI的统一底座。存数据只是起点,融数据才是关键;有模型只是表象,模数同频才是未来。数栈7.0多模态数据底座,助力企业紧跟模数共振浪潮,把数据孤岛变成数据资产
