
写文章




- @a519573917
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
2007-2021年36家上市银行绿色信贷余额、绿色信贷占比、资产收益率、不良贷款率等数据
绿色信贷的概念最早由国际金融公司(IFC)在 2003 年提出,是指银行等金融机构向符合环保标准的企业和项目提供的贷款。
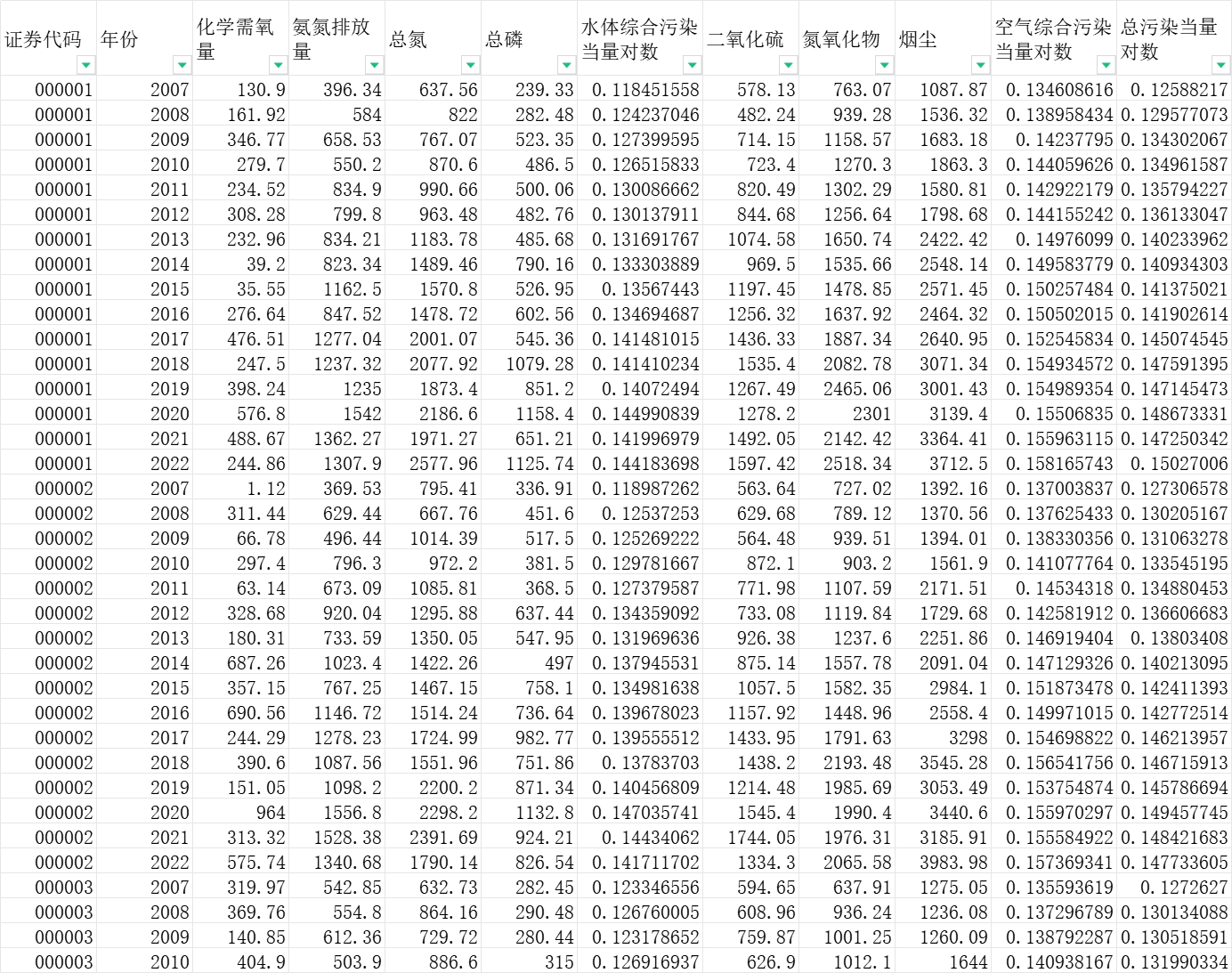
2000-2022年上市公司数字化转型与绿色创新质量匹配数据(含控制变量)
本文旨在研究上市公司数字化转型与绿色创新质量匹配的关系。通过构建实证模型,利用2000-2022年上市公司的相关数据进行回归分析。

久期分析与久期模型
从数学角度来看,久期是债券现金流的加权平均时间,其中权重是现金流的现值占债券总现值的比例。反之,久期越短,债券价格对利率变动的敏感性越低。它不仅仅是一个简单的时间概念,更是反映了债券现金流回收的平均时间,同时也体现了债券价格与利率之间的非线性关系。以一个简单的固定利率债券为例,如果债券每年支付固定的利息,到期时偿还本金,那么久期的计算就是将每一期现金流的时间乘以其现值,然后求和,再除以债券所有现金

《面板计数模型及 Stata 具体操作步骤》
例如,Lee 和 Kim(2015)利用面板计数模型对互联网用户的在线购物行为进行了分析,研究用户在不同时间点的购物次数与用户的人口统计学特征、消费习惯、网站推荐等因素之间的关系。在医学领域,Johnson 和 Brown(2012)使用面板计数模型研究了患者的就医行为,特别是患者在一段时间内的就诊次数与患者的年龄、性别、健康状况、医疗保险等因素之间的关系。计数变量则是取值为非负整数的变量,常见的

2000-2022年上市公司数字化转型与绿色创新质量匹配数据(含控制变量)
本文旨在研究上市公司数字化转型与绿色创新质量匹配的关系。通过构建实证模型,利用2000-2022年上市公司的相关数据进行回归分析。
到底了