




- @Tassel_YUE
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要: 当Linux系统出现CPU负载高但使用率低时,通常由I/O或内核等待导致。排查步骤包括: 确认负载与核数关系:uptime与nproc对比,判断负载是否超标。 分析CPU状态:top查看wa(I/O等待)、st(虚拟化抢占)等指标。 定位D状态进程:ps命令筛选D状态进程,结合wchan字段判断卡顿原因(如磁盘I/O、NFS、锁等待)。 检查I/O性能:iostat/vmstat关注%ut
Google Gemini 3 Pro展示了强大的AI编程能力,通过实例演示了其响应复杂Prompt的能力。用户请求开发一个完整的双人黑八台球HTML游戏,Gemini不仅生成了完整的游戏代码,还解决了初始版本的两个关键问题:1)支持鼠标超出桌面区域的大力度击球操作;2)修复进球后无法继续操作的问题。生成的代码包含物理引擎、游戏状态管理和UI交互,可直接保存为HTML文件运行。该案例展示了Gemi
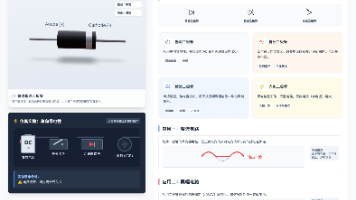
目前网络上已经有很多关于Zabbix如何推送告警信息到钉钉机器人、到邮件等文章。但是在搜索下来,发现缺少了对告警信息的美化的文章。本文不赘述如何对Zabbix对接钉钉、对接邮件,仅介绍我采用的美化消息模板的内容。活用AI工具可以减轻很多学习、脑力负担。本文采用了与deepSeek、Chatgpt-4o两款模型对话,最后给出了如下的美化内容。

通过土耳其区Apple ID购买GPT Plus会员可节省费用(约80-90元人民币)。方法包括:1)注册土区Apple ID(需土耳其身份信息);2)通过Oyunfor等平台购买土耳其区苹果礼品卡充值(约515里拉兑换500里拉);3)在App Store下载ChatGPT并使用余额开通Plus会员。需注意支付时填写土耳其地址,且礼品卡仅限土区使用。
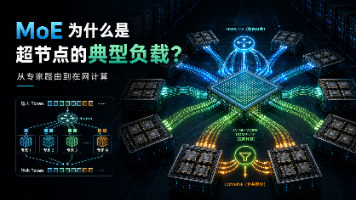
摘要: 超节点工程化是AI基础设施稳定运行的关键,涉及可靠性分层设计(器件、链路、系统、任务)、无损网络技术(PFC/ECN/FEC等)和拓扑感知调度。故障模型需按任务影响路径分析,而非简单硬件状态。华为、中兴、H3C报告指出,超节点运维需融合硬件监控与训练指标,实现秒级故障隔离与自愈。重点包括:通过RAS机制应对万级处理器故障常态,通过训前巡检降低环境风险,以及调度器需理解模型并行结构(TP/E

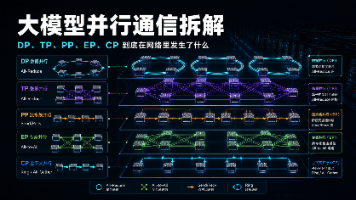
摘要 本文基于华为、中兴、H3C的技术报告,深入分析MoE(混合专家)模型在超节点系统中的通信瓶颈。MoE通过动态路由token到不同专家子网络,虽然节省计算量,但引入了复杂的All-to-All通信问题。关键发现包括: 单层MoE至少包含Dispatch和Combine两段跨设备通信路径; EP(专家并行)扩大后,专家计算压力下降,但token交换量增加,热点专家会导致网络拥塞和尾时延; 超节点
DP 关注大流量归约和分层通信。TP 关注层内高频低时延。PP 关注阶段通信和流水线气泡。EP 关注 All-to-All、热点和尾时延。CP/SP 关注长序列下通信、缓存和内存协同。超节点的价值,就是让训练平台可以把这些通信放到合适的网络层里,而不是让所有流量都挤在同一张网络上。
超节点技术推动统一内存编址与资源池化发展 摘要:本文基于华为、中兴、H3C的技术报告,分析了超节点架构中统一内存编址的关键技术演进。超节点通过超大带宽(提升15倍)和超低时延(降至200纳秒)互联,实现了从高速通信到统一地址空间的跨越。报告指出,统一内存编址需要解决地址层(全局寻址)、访问层(DMA/RDMA/Load-Store多语义)和管理层(资源调度)三大问题。CXL技术在此过程中扮演重要角

摘要 本文探讨了AI超节点中Scale-Up互联的技术价值,指出传统Scale-Out集群在处理大模型高频通信时的局限性。超节点通过构建高带宽域(HBD),将强耦合通信(如张量并行、专家并行)限制在机柜级紧耦合系统内,缓解跨服务器网络的带宽断层问题。分析表明,评估Scale-Up方案需综合考量单卡带宽、时延、拓扑跳数、收敛比等指标,而非仅关注总带宽。华为、中兴、H3C的技术报告均强调,超节点的核心

摘要 本文探讨了AI超节点中Scale-Up互联的技术价值,指出传统Scale-Out集群在处理大模型高频通信时的局限性。超节点通过构建高带宽域(HBD),将强耦合通信(如张量并行、专家并行)限制在机柜级紧耦合系统内,缓解跨服务器网络的带宽断层问题。分析表明,评估Scale-Up方案需综合考量单卡带宽、时延、拓扑跳数、收敛比等指标,而非仅关注总带宽。华为、中兴、H3C的技术报告均强调,超节点的核心