




- @T940842933
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在模型选定后,一般还需进行模型的参数调优工作,介绍两种模型调优的基本方式:网格搜索寻优(Grid Search CV)和随机搜索寻优(Randomized Search CV)

模型选择,又称超参数选择,目的是确定模型使用的超参数具体的过程:首先在训练集和验证集上对多种模型选择(超参数选择)进行验证,选出平均误差最小的模型(超参数)。选出合适的模型(超参数)后,可以把训练集和验证集合并起来,重新把模型训练一遍,得到最终模型,然后再用测试集测试其泛化能力。
本文详细介绍了线性回归的基本原理和过程,展现了线性回归模型的scikit-learn实现,包括:普通线性回归、基于 L1 正则化的Lasso回归、基于 L2 正则化的岭回归、基于 L1 和 L2 正则化融合的ElasticNet回归四种,从结果看ElasticNet回归模型的性能最优不足的一点,模型的参数是随意取值的,由于没有做模型优化,所以四种模型的预测准确率都不是特别高,而且四种模型的区分度也
模型选择,又称超参数选择,目的是确定模型使用的超参数具体的过程:首先在训练集和验证集上对多种模型选择(超参数选择)进行验证,选出平均误差最小的模型(超参数)。选出合适的模型(超参数)后,可以把训练集和验证集合并起来,重新把模型训练一遍,得到最终模型,然后再用测试集测试其泛化能力。
机器学习是概率论、线性代数、信息论、最优化理论和计算机科学等多个领域交叉的学科传统编程模式:规则+数据——>传统编程——>答案机器学习模式:数据+答案——>机器学习——>规则机器学习特点:以计算机为工具平台,以数据为研究对象,以学习方法为中心研究包括:(1)机器学习方法:旨在开发新的学习方法(2)机器学习理论:旨在探求机器学习的有效性和效率(3)机器学习应用:主要考虑机器学习模型应用到实际中去,解
K-Means 算法是一种无监督的聚类算法,其核心思想是:对于给定的样本集,按照样本点之间的距离大小,将样本集划分为K个簇,并让簇内的点尽量紧凑,簇间的点尽量分开算法流程图如下:K-Means算法流程如图,以为例:我们需要将图(a) 中的样本点划分为两类,则K-means聚类过程如下:第 1 步:从M个数据对象中任意选择2个对象作为初始聚类中心,如图(b) 所示。
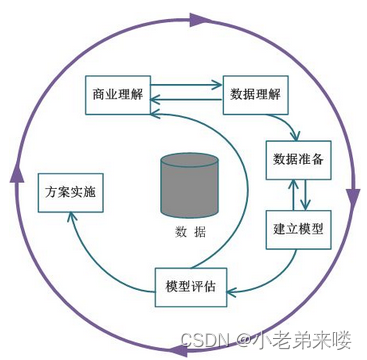
一个完整的数据挖掘项目流程主要包含六大部分,分别是商业理解、数据理解、数据准备、建立模型、模型评估、方案实施,如图所示数据挖掘项目流程。
本文详细介绍了线性回归的基本原理和过程,展现了线性回归模型的scikit-learn实现,包括:普通线性回归、基于 L1 正则化的Lasso回归、基于 L2 正则化的岭回归、基于 L1 和 L2 正则化融合的ElasticNet回归四种,从结果看ElasticNet回归模型的性能最优不足的一点,模型的参数是随意取值的,由于没有做模型优化,所以四种模型的预测准确率都不是特别高,而且四种模型的区分度也
一个完整的数据挖掘项目流程主要包含六大部分,分别是商业理解、数据理解、数据准备、建立模型、模型评估、方案实施,如图所示数据挖掘项目流程。