




- @QinZheng7575
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了离散动作空间下SAC(Soft Actor-Critic)算法的实现要点。与连续版本不同,离散SAC需要让策略输出所有动作的概率分布,并通过加权求和直接计算期望值。
最近因为寒假即将结束,也要继续毕设的工作了,但是在回归pytorch学习的时候,遇到很大问题,烦了我挺长一段时间,终于解决。由于《动手学深度学习Pytorch》一书中需要torchtext包,围绕着这个包的安装,我踩了不少雷。但是在这解决问题们的过程中,获得了很多知识,收纳下来吧。torchtext安装问题现有的很多博客的教程都有很大问题!如果直接用pip install torchtext,会给
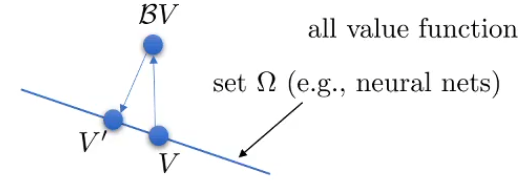
强化学习大多数不是理论收敛的,本文就给出了原因和证明思路。接着我们讨论Double Q-Learning和在连续动作下的强化学习DDPG
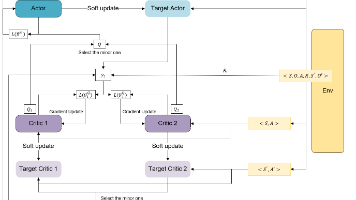
SAC(Soft Actor-Critic)算法是一种基于熵最大化的Off-Policy Actor-Critic方法,擅长处理连续动作空间问题。其核心思想是通过最大化策略的随机性来鼓励探索,避免局部最优。算法使用两个Critic网络(SoftQNetwork)实现Clipped Double-Q Learning,并通过Actor网络输出动作的概率分布。
强化学习大多数不是理论收敛的,本文就给出了原因和证明思路。接着我们讨论Double Q-Learning和在连续动作下的强化学习DDPG
基于模型的强化学习,介绍原理,并且后面介绍隐式的,基于部分可观测的MDP的强化学习

typora-copy-images-to: …\MD_note\images目前整理新看的一些论文:动态分簇《Adaptive Client Selection in Resource Constrained Federated Learning Systems: A Deep Reinforcement Learning Approach》这篇文章核心思想:你不知道哪些设备可能没能力去参与运算
量化改进的联邦学习,采用pysyft为联邦基础框架。重点在于探讨量化再实际通信场景下的对联邦学习效率的影响。
强化学习大多数不是理论收敛的,本文就给出了原因和证明思路。接着我们讨论Double Q-Learning和在连续动作下的强化学习DDPG
在给一个项目写可视化的时候,项目需要用iperf3来进行网络测试。遇到了subprocess与多线程问题,后来解决