




- @Prelude4
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
JWT是一种用户认证机制,服务器在用户登录后生成加密令牌,前端存储该令牌并用于后续请求验证。具体流程:1.后端验证登录信息后生成含用户数据的JWT并返回;2.前端将JWT存入浏览器本地存储(如localStorage);3.后续请求通过拦截器自动附加JWT至请求头。令牌可解码获取用户信息,过期后需重新登录。该方案实现无状态认证,适用于前后端分离架构。
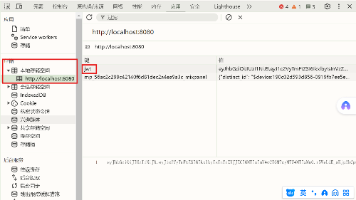
简单来说,在Vue 项目中,文件是一个可选的配置文件,它允许开发者自定义项目的各种设置,以满足特定需求。更详细的介绍本博客只介绍如何在此全局配置url。

在run——edit configuation这里,并且点开需要编辑的脚本。里面,需要先检查pycharm有没有指定启动方式——选择了一个之后会自动地出现在下面。如果没有的话,需要选上启动方式。

深度学习模型训练加速技术综述 随着模型规模扩大,训练面临四大瓶颈:IO、计算、显存和通信。针对这些问题,文中提出了一系列优化方案: IO优化:采用数据预取、固定内存和ZeroCopy技术减少数据传输延迟;权重分片和按需加载缓解显存压力。 2.计算优化:通过算子融合减少显存访问;混合精度训练提升计算效率;编译优化合并算子执行。 3.显存优化:重计算技术选择性保存中间结果,大幅降低显存消耗。 4.通信
温度,是 softmax 中的一个缩放因子。你可以把 logits 除以一个温度值 TT 后再传给 softmax:当 T=1T = 1:模型按默认方式工作 —— 平衡输出,理性回答。当 T>1T > 1:高温会“软化” logits 分布,使得概率变得更加平均,低概率的词有更多机会被选择。输出更多样、更具想象力。当 T<1T < 1:低温会“强化” logits 差异,使得概率更加集中,模型只信
深度学习模型训练加速技术综述 随着模型规模扩大,训练面临四大瓶颈:IO、计算、显存和通信。针对这些问题,文中提出了一系列优化方案: IO优化:采用数据预取、固定内存和ZeroCopy技术减少数据传输延迟;权重分片和按需加载缓解显存压力。 2.计算优化:通过算子融合减少显存访问;混合精度训练提升计算效率;编译优化合并算子执行。 3.显存优化:重计算技术选择性保存中间结果,大幅降低显存消耗。 4.通信
温度,是 softmax 中的一个缩放因子。你可以把 logits 除以一个温度值 TT 后再传给 softmax:当 T=1T = 1:模型按默认方式工作 —— 平衡输出,理性回答。当 T>1T > 1:高温会“软化” logits 分布,使得概率变得更加平均,低概率的词有更多机会被选择。输出更多样、更具想象力。当 T<1T < 1:低温会“强化” logits 差异,使得概率更加集中,模型只信