




- @OneThingAI
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:DeepSeek团队低调发布V3.1大模型,延续其一贯"夜间突袭"风格。该版本主要升级包括:上下文窗口从128K扩展至100万token、增强复杂推理与多语言处理能力、优化工具调用格式(更简洁的函数参数传递方式),并引入可切换的思维模式。技术架构保持671B总参数规模,采用稀疏MoE与MLA注意力机制。测试显示其物理理解和代码能力有所提升,通过"思考-搜索-工具
这是一个关键的经济优化:Claude Code 的 prompt 缓存文档指出,缓存命中时输入 token 的价格仅为未缓存的 10%。独立验证来自 Tekkix 的技术分析,该分析在更大的代码库上重现了类似结果:VS Code(4002 文件)从 52 次工具调用降至 3 次(94% 减少),Swift 编译器(25,874 文件、272,898 节点)在 4 分钟内完成索引,Agent 以 6

这是一个关键的经济优化:Claude Code 的 prompt 缓存文档指出,缓存命中时输入 token 的价格仅为未缓存的 10%。独立验证来自 Tekkix 的技术分析,该分析在更大的代码库上重现了类似结果:VS Code(4002 文件)从 52 次工具调用降至 3 次(94% 减少),Swift 编译器(25,874 文件、272,898 节点)在 4 分钟内完成索引,Agent 以 6
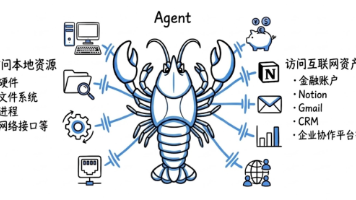
一个理想的小模型 Agent,应当在模型契约层有可靠的结构化调用能力,在生态层接入 MCP 这样的标准化工具网络。在金融领域的 8 类任务中,<10B 模型在需要多步推理的任务上(如因果分析、趋势预测)与大模型的差距最大,且增加 Agent 工具并不能弥补推理缺陷,工具帮助的是信息获取,而非逻辑推理。3.8B 的 Phi-4-mini 在 AIME 2025(美国数学奥林匹克预选赛)上接近了 67
一个理想的小模型 Agent,应当在模型契约层有可靠的结构化调用能力,在生态层接入 MCP 这样的标准化工具网络。在金融领域的 8 类任务中,<10B 模型在需要多步推理的任务上(如因果分析、趋势预测)与大模型的差距最大,且增加 Agent 工具并不能弥补推理缺陷,工具帮助的是信息获取,而非逻辑推理。3.8B 的 Phi-4-mini 在 AIME 2025(美国数学奥林匹克预选赛)上接近了 67
摘要: 基础模型能力提升后,Agent系统的表现差异主要源于外部控制栈(AgentHarness)的设计。Harness负责工具调用、状态管理、异常恢复等,决定了模型能力的实际发挥水平。行业共识表明,Agent竞争已从模型能力转向系统工程优化。OpenAI、Anthropic等通过分层治理(行动接口、观测回路、状态管理等)提升稳定性,而Meta-Harness则探索自动化优化Harness的方法。
NVIDIA在GTC2026大会上发布的NemoClaw是一款面向AI Agent的安全运行时解决方案。作为OpenClaw的安全基座,NemoClaw采用操作系统级隔离技术(Landlock LSM、seccomp BPF等)构建安全沙箱,通过四层架构实现细粒度管控:CLI插件层提供交互入口,蓝图编排层实现声明式部署,OpenShell沙箱层提供强制隔离,推理路由层保障API密钥安全。该方案解决
我们分析过目前一般使用的 Attention 的计算,是当前的 query 和历史上所有的 key 的内积所产生的 attention score,然后对所有历史输入 token 的 value 进行加权平均后得到 context。未来,基于这个架构已呈现出的原生能力的基础上,如果我们给它一些更高质量的数据,让它学到更多世界知识的同时,补充更高强度的强化学习过程,一定会展现出更强的能力。mHC 的

作为 DeepSeek V4 系列的全新模型,V4-Pro 在逻辑推理、代码开发、长文本理解、专业创作等核心能力全面升级,综合实力稳居开源模型第一梯队。数学、STEM、竞赛型代码推理能力,超越当前所有已公开评测的开源模型,实现与顶级闭源模型同级的推理表现。:参考说明文档提供的 Python、Go、Node 等多语言示例,将 DeepSeek-V4-Pro 模型接入你的业务逻辑。,相比传统方案大幅降

摘要:Anthropic将Claude从模型API升级为Managed Agents,反映出AI行业正从单纯追求模型能力转向构建完整的Agent系统。核心观点包括:1)Agent的核心价值在于模型之外的系统层(harness、runtime和infra);2)上下文管理成为关键,低效的prefix cache复用会导致高昂成本;3)好的harness需要解决稳定前缀、工具规范化、上下文分层等七大问
