- @Liuxw666666
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
GC出问题了,整体上就要从两个方面去考虑,一是自己写的程序代码是不是有问题,由于我这里的代码很简单,只是见到的执行了一个sql,而且sql没有更好的优化方案了,所以排除了程序代码的问题;二就是相应的内存是不是给的少了,因为这里要处理的表的数据量特别大,不是java经常操作的mysql这种数据库处理的量级,所以第一时间去看了spark-shell的执行脚本里的一些配置,也从网上百度了一些博客,有的告

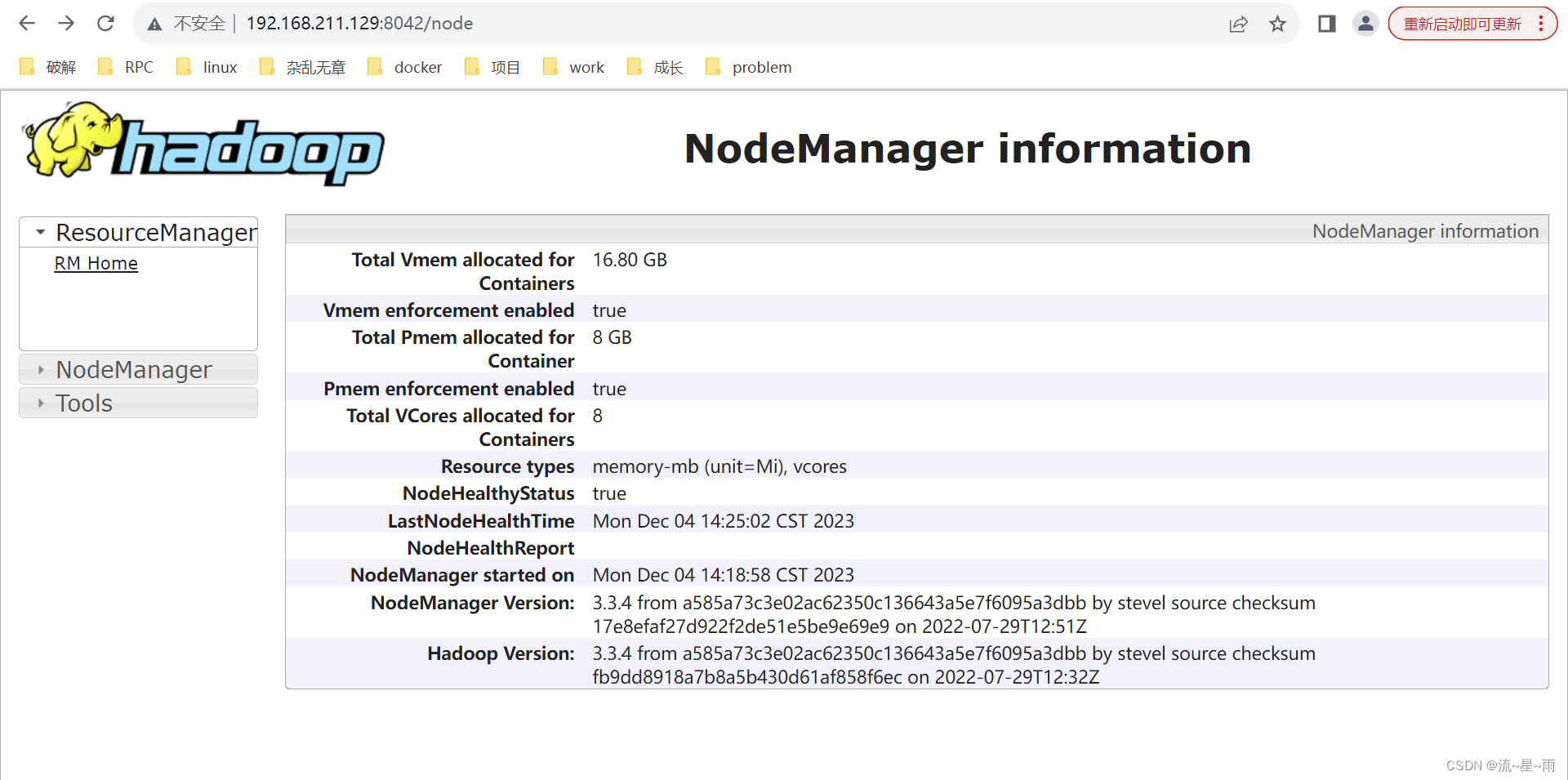
工作中遇到了大数据方面的一些技术栈,没有退路可言,只能去学习掌握它,就像当初做爬虫一样(虽然很简单),在数据爆发的现在,传统的数据库mysql,oracle显然在处理大数据量级的数据时显得力不从心,所以有些特定的业务需要引进能够处理大数据量的数据库,hadoop提供了分布式文件系统(HDFS)来存储数据,又提供了分布式计算框架(mapreduce)来对这些数据进行处理,另一个hadoop的核心组件

GC出问题了,整体上就要从两个方面去考虑,一是自己写的程序代码是不是有问题,由于我这里的代码很简单,只是见到的执行了一个sql,而且sql没有更好的优化方案了,所以排除了程序代码的问题;二就是相应的内存是不是给的少了,因为这里要处理的表的数据量特别大,不是java经常操作的mysql这种数据库处理的量级,所以第一时间去看了spark-shell的执行脚本里的一些配置,也从网上百度了一些博客,有的告
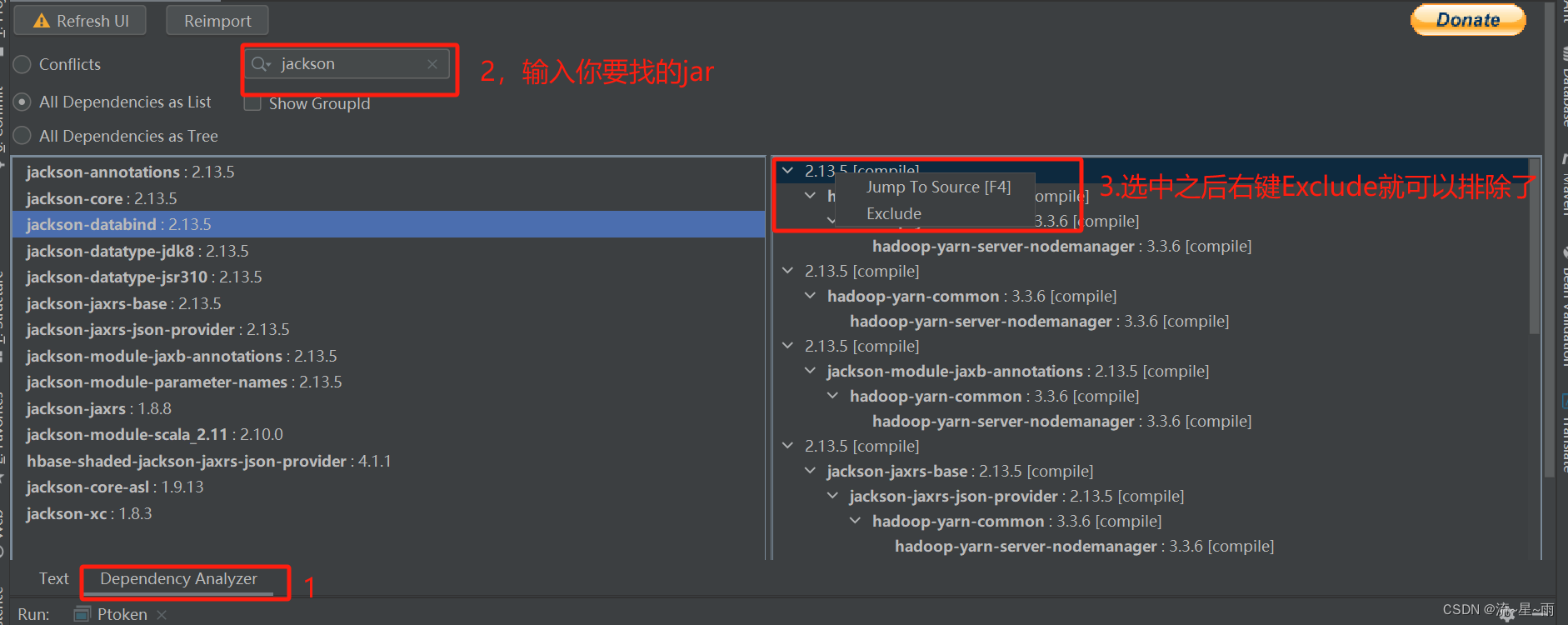
最近工作接了一个坑,要做一个项目的组件版本升级,就是maven项目通过pom.xml文件管理的jar包,之前没有过这方面的工作经验,在这里记录一下遇到的问题,以及自己简单的经验。1.第一步肯定是要去maven仓库里找到自己要升级的版本了,可能是指定你升级到哪个版本,或者是让你做一些漏洞升级,没有给你指定版本,这就更要去仓库里找到自己需要的版本号了。。在这里直接搜自己想要查找的jar即可。2.找到自
工作中遇到了大数据方面的一些技术栈,没有退路可言,只能去学习掌握它,就像当初做爬虫一样(虽然很简单),在数据爆发的现在,传统的数据库mysql,oracle显然在处理大数据量级的数据时显得力不从心,所以有些特定的业务需要引进能够处理大数据量的数据库,hadoop提供了分布式文件系统(HDFS)来存储数据,又提供了分布式计算框架(mapreduce)来对这些数据进行处理,另一个hadoop的核心组件

hive中我也都创建好了表,其中t_gdp是原始数据表,tmp_gdp_table是和hbase中gdp表关联的外部表,我这里因为只是一个简单的示范,只是将t_gdp表中的数据insert到了tmp_gdp_table表中,正常的业务中,可能是查询了多个表,通过sql处理将数据存到tmp_gdp_table中,然后通过外部表映射的方式同步到habse的gdp表中。好了,想介绍的都说完了,我下面的操
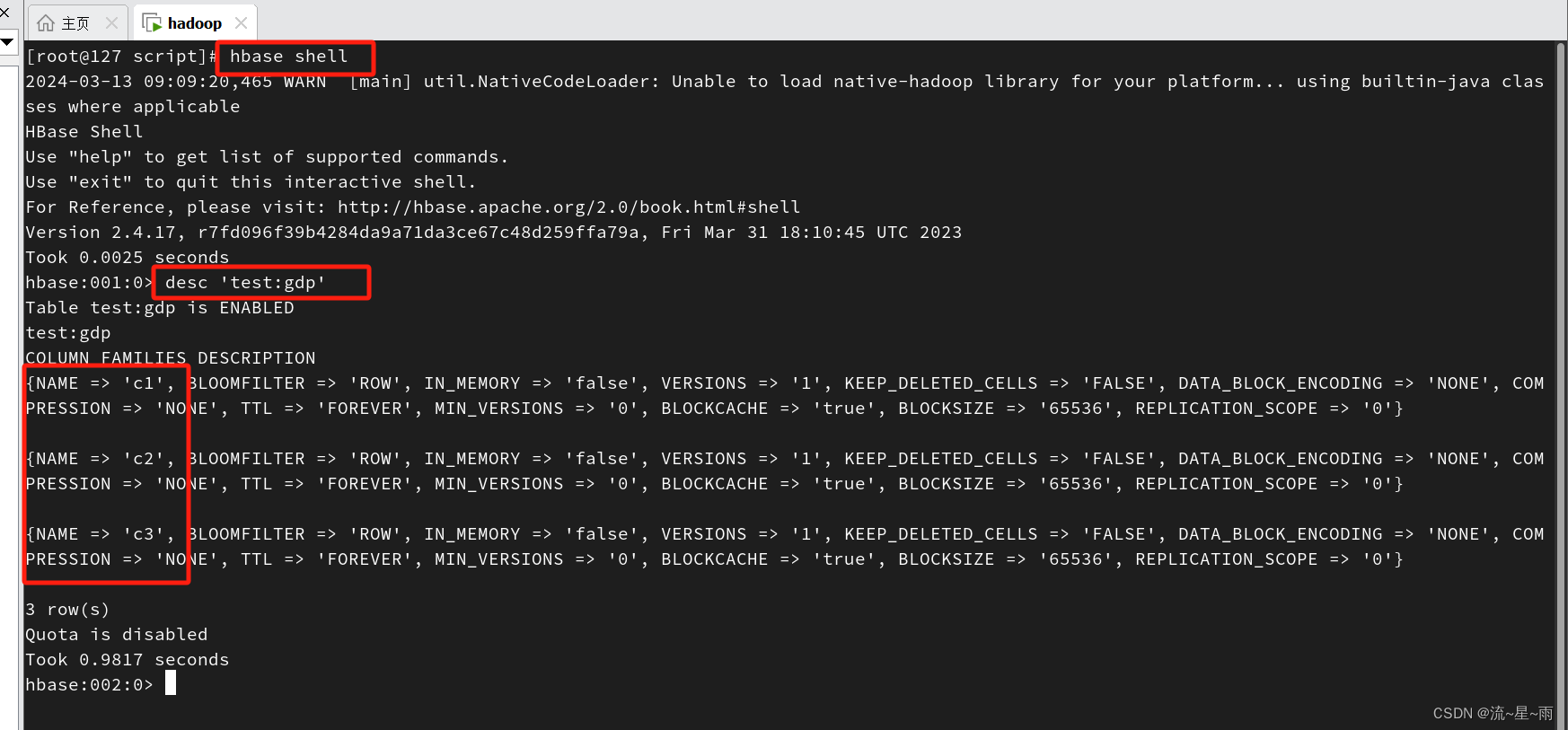
hive是我打算了解的有一个大数据方面的一个技术栈,上一篇介绍了Hadoop和hbase,有兴趣的朋友可以点击“文章”浏览,今天要介绍的hive也是要基于hadoop的,安装hive也要提前安装好hadoop。刚了解这块的朋友肯定就会疑问这三者之间的关系是什么呢,从我这段时间对它们的简单了解,我的理解是,hadoop是根本,它通过分布式存储,分布式计算的方式从而提供了存储,处理大数据量的能力。