- @LiuSid7
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Claude Code 会自动读取你文件夹里的内容,思考步骤,然后询问你是否允许它直接修改文件。注意:你的每一次代码修改、每一次提问,系统都会根据消耗的字符数从这笔预充值金里扣除极小额的费用。Claude Code 采用的是“用多少扣多少”的开发者 API 计费模式。(注:要让第二步的安装命令生效,你的电脑必须先具备以下运行环境。“解释一下 index.js 里的这段代码是干什么用的。“在这个项目

通过对这 50 万行代码的解剖,我们发现 Claude Code 绝非简单的“终端对话框”,它展示了 Anthropic 对。即便是在 AI 狂奔的今天,这也是足以载入史册的工程意外:Anthropic 在发布。这次泄露的本质非常朴素:搬家时把锁在保险柜里的日记副本,贴在了纸箱外面。在极其硬核的逻辑库中,Anthropic 的工程师竟然塞进了一套完整的。这不仅是一场公关灾难,更是一扇通往 AI A
最近有不少听闻cc的大名跑来上手新工具的朋友,但是cil的页面让不少对命令行不熟悉的朋友感到疑惑。不知道如何下手。今天笔者在这里分享一下我根据官方文,内容很长,建议作为工具书使用:主要内容: - 六种不同平台的详细安装方法,包括 Docker 和源码编译 - MCP 集成完整指南,连接外部服务和数据库的配置教程 - 完整的命令参考表,覆盖 CLI 命令和交互模式斜杠命令 - 安全权限管理和最佳实践
通过对这 50 万行代码的解剖,我们发现 Claude Code 绝非简单的“终端对话框”,它展示了 Anthropic 对。即便是在 AI 狂奔的今天,这也是足以载入史册的工程意外:Anthropic 在发布。这次泄露的本质非常朴素:搬家时把锁在保险柜里的日记副本,贴在了纸箱外面。在极其硬核的逻辑库中,Anthropic 的工程师竟然塞进了一套完整的。这不仅是一场公关灾难,更是一扇通往 AI A
Chaterm支持Command与Agent两种模式,Command模式的定位是用户辅助,类似于辅助驾驶,是AI辅助人来生成指令,在当前已有的终端会话中执行命令。Chaterm是一款AI驱动的终端工具,相比传统终端工具,除了加入诸多的AI Agent能力,也加入了比如零信任认证等大量安全性相关的能力,目前该项目刚刚发布,我们期待这款工具在未来能有更优秀的表现!:可配置的全局Alias,给复杂的命令
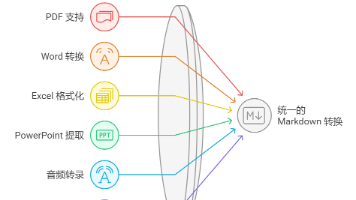
是一个轻量级的 Python 工具,用于将各种文件转换为 Markdown,以便与 LLMs 和相关的文本分析管道一起使用,将重要的文档结构和内容作为 Markdown 保留(包括:标题、列表、表格、链接等)。
摘要: Langflow是一款可视化AI Agent开发工具,支持通过拖拽界面快速构建大语言模型(LLM)工作流。其核心优势包括: 低代码开发:提供积木式可视化编辑器,无需深厚编程基础即可搭建复杂Agent流程; 全栈兼容性:支持OpenAI、Claude、Gemini等主流模型及Pinecone等向量数据库,覆盖RAG等高级场景; 高效部署:支持一键生成API接口或JSON导出,便于系统集成;
Chaterm支持Command与Agent两种模式,Command模式的定位是用户辅助,类似于辅助驾驶,是AI辅助人来生成指令,在当前已有的终端会话中执行命令。Chaterm是一款AI驱动的终端工具,相比传统终端工具,除了加入诸多的AI Agent能力,也加入了比如零信任认证等大量安全性相关的能力,目前该项目刚刚发布,我们期待这款工具在未来能有更优秀的表现!:可配置的全局Alias,给复杂的命令
本文展望 2026 年普通人将拥有的 AI 生活助手,描绘其从被动指令执行者进化为主动式 Personal AI Agent 的图景。通过本地大模型实现跨场景协同与隐私保护,提供懂生活的智能服务,助力用户提前培养数字习惯迎接未来。
本文详细介绍了如何从零开始搭建Claude Code与Figma的连接工作流,实现设计修改时自动生成前端代码的功能。教程包含7个关键步骤:安装Claude Code(需先安装Cursor编辑器)、接入API(推荐使用国内GLM4.6模型)、下载配置CC Switch工具、启动Claude Code、连接Figma MCP、安装Figma插件,以及常见报错解决方案。作者特别提示使用国内API更经济实