




- @LIUMAO99
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文系统分析了大模型分布式训练的三大主流框架:Megatron-LM、DeepSpeed和LLaMA-Factory的技术特点与适用场景。Megatron-LM作为英伟达原生并行引擎,在超大规模模型训练中展现极致性能;DeepSpeed以ZeRO优化技术为核心,显著降低显存占用,成为RLHF训练的首选方案;LLaMA-Factory则通过封装HuggingFace生态,提供开箱即用的微调体验。
本文深入剖析机器学习的三大核心范式——监督学习、无监督学习和强化学习。通过大量生动的代码实例,详细解读每种范式的原理、应用场景及优缺点。无论是初学者还是进阶者,都能在代码实战中快速掌握这些关键知识,领略机器学习的强大魅力,开启智能算法的探索之旅。

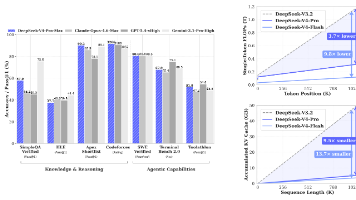
DeepSeek V4是2026年发布的开源大语言模型,具备三大技术突破:1)混合注意力系统(CSA+HCA)将百万级上下文处理成本降低70%;2)流形约束超连接(mHC)解决万亿参数稳定性问题;3)Muon优化器提升40%训练效率。模型提供1.6万亿参数的Pro版和2840亿参数的Flash版,均支持100万token上下文,在长文本、代码等场景性能媲美顶级闭源模型。采用MIT协议完全开源,支持
PPO算法:强化学习的工业级解决方案 PPO(近端策略优化)算法通过引入“信任区域”思想,解决了传统策略梯度算法因更新步长过大导致的训练不稳定问题。PPO的核心创新在于使用截断机制(Clipping)或自适应KL散度约束策略更新幅度,仅需一阶优化即可实现稳定训练,平衡了样本效率与实现复杂度。其Actor-Critic架构结合策略网络和价值网络,通过广义优势估计(GAE)计算优势函数,指导策略优化。
JEPA(联合嵌入预测架构)是Yann LeCun提出的一种新型自监督学习范式,其核心思想是在抽象表征空间而非输入空间进行预测。该架构由上下文编码器、目标编码器和预测器组成,通过掩码策略和非对称设计学习数据的内在结构。相比生成式和对比学习方法,JEPA具有计算效率高、语义抽象性强和模态通用性好等优势,已在图像、视频、音频等多领域验证有效性。作为构建世界模型的基础架构,JEPA展现了在自动驾驶、机器
ModelContextProtocol(MCP)作为AI模型与外部工具交互的标准化协议,自2024年提出以来快速发展。其采用三层架构设计,通过工具、资源、提示三大原语实现智能体与外部系统的高效交互。在电商、金融、医疗等行业应用中成效显著。

DeepSeek V4是2026年发布的开源大语言模型,具备三大技术突破:1)混合注意力系统(CSA+HCA)将百万级上下文处理成本降低70%;2)流形约束超连接(mHC)解决万亿参数稳定性问题;3)Muon优化器提升40%训练效率。模型提供1.6万亿参数的Pro版和2840亿参数的Flash版,均支持100万token上下文,在长文本、代码等场景性能媲美顶级闭源模型。采用MIT协议完全开源,支持
摘要:本文基于B站科普视频,系统解析人工智能领域的三大核心概念:Prompt(提示词)作为用户与AI的交互指令,是需求传递的基础;Agent(智能体)作为任务调度中枢,具备自主决策和执行能力;MCP(模型上下文协议)则是标准化通信协议,保障AI组件间的协作。三者形成"交互层-处理层-通信层"的协作体系,共同支撑AI从被动问答向主动完成复杂任务的进化。研究表明,理解这些概念的定位
线性RNN实现并行计算的核心在于其线性递推关系满足结合律,从而能够通过并行扫描算法将串行计算深度压缩至对数级别。线性RNN的纯线性状态转移特性使其能够定义满足结合律的复合算子,而传统非线性RNN因包含激活函数无法实现。并行扫描分两个阶段:向上规约阶段自底向上合并子段操作元,向下传播阶段计算各位置前缀结果。该方法在GPU上可显著加速训练(尤其长序列场景),同时保持推理时的串行效率。这种架构已应用于M
本文系统分析了大模型推理中注意力机制的技术演进路线,聚焦KVCache显存瓶颈问题。从标准多头注意力(MHA)到多查询注意力(MQA)、分组查询注意力(GQA)和最新的多头潜在注意力(MLA),四种方案在模型质量、显存占用和推理速度三个维度呈现不同权衡:MHA保持无损质量但资源效率最低;MQA实现极致压缩但质量损失明显;GQA在8分组时找到平衡点;MLA通过低秩联合压缩在长序列场景展现出压倒性优势