




- @Janeiskangs
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
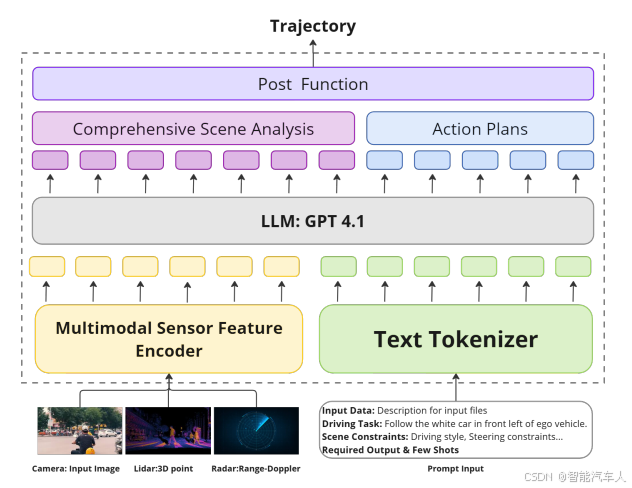
本文提出了一种新型自动驾驶框架PLA(感知-语言-行动),通过整合多模态感知、语言增强认知和分层决策,解决了传统模块化系统的误差累积和端到端模型的短视决策问题。该框架采用双分支视觉编码器处理几何与语义信息,引入混合思维推理机制动态选择决策路径,并利用语言模型提供常识知识。实验表明,PLA在轨迹误差、碰撞率等指标上表现优异,尤其在极端场景下展现出更强的适应性和解释性。这一突破标志着自动驾驶向类人认知
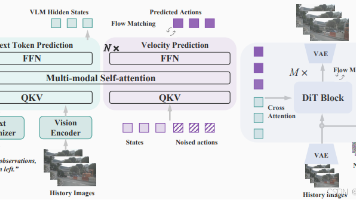
UniUGP提出了一种"理解-生成-规划"三位一体的端到端自动驾驶框架,解决了传统模块化架构的误差累积、协同不足和算力冗余问题。通过统一特征表征层和多任务协同推理层,实现了场景语义理解、多模态轨迹生成和决策规划的深度融合。实验表明,相比UniAD等方法,UniUGP在轨迹精度(≤0.30m L2误差)、安全性(≤0.20%碰撞率)和实时性(≤15ms延迟)方面均有提升。其创新在
Freeze训练是一种深度学习模型微调技术,通过冻结预训练模型的大部分参数(如Transformer层),仅调整部分关键层或新增模块,从而显著降低计算资源消耗。该方法在大型语言模型(LLM)应用中优势明显:节省算力、防止小数据过拟合、灵活适配不同任务。但需注意合理选择冻结层、调整学习率,并确保数据质量。实践经验表明,结合LoRA等新技术能进一步提升效率,建议从小任务入手并记录实验配置。Freeze

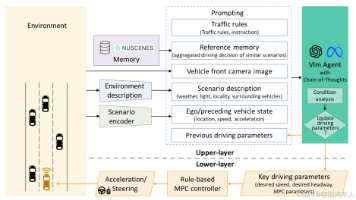
本文提出了一种结合视觉语言模型(VLM)与模型预测控制(MPC)的自动驾驶分层控制架构VLM-MPC。该系统通过异步双模块设计解决传统端到端控制的可解释性差和动态适应性不足问题:上层VLM(0.2Hz)利用CLIP模型解析环境语义生成驾驶参数,下层MPC(10Hz)基于参数进行实时控制。关键技术包括环境编码器、参考记忆模块和抗幻觉设计,在nuScenes数据集实验中显示出优于基线的安全性和舒适性。
目前机器人的技术随着驱动方式的变化,控制越来越成熟,在自主无人化方面随着大模型的发展也会逐渐进化,但对于未来的应用场景和市场化方面仍然需要进一步挖掘。

人形机器人领域的快速发展,正成为全球科技竞争的新焦点。从宇树机器人的“功夫秀”到众擎科技的“前空翻”,国产人形机器人正在以惊人的速度崛起,不仅展现了技术实力,更向世界展示了中国在这一领域的创新能力。人形机器人将为人类社会带来前所未有的变革。随着技术的进一步成熟和成本的逐步降低,人形机器人有望从工业领域扩展到教育、医疗、养老甚至日常生活中。它们将成为人类的助手、伙伴,甚至是家庭成员的一部分。随着未来

加州理工学院团队研发的ATMO地空两用机器人,采用创新设计实现0.3秒快速形态转换。研究对比了强化学习(RL)与模型预测控制(MPC)策略:RL在极限工况下表现更优(最大着陆倾角65°、抗干扰能力强),而MPC姿态控制更精准(±3°滚转振荡)。实验显示RL在推进器故障时仍能稳定着陆,但存在通信延迟敏感问题。该成果发表于IROS2025,为多模态机器人控制提供了新思路,未来可应用于物流、救援等领域。

同智能汽车一样,人形机器人也会是未来机器人领域的一个重要分支。目前地球上最高智慧的结晶体就是人类,那么人形机器人的未来会有非常大的发展空间。虚拟的人形机器人可用于办公,日常对话等,实体的人形机器人可用于人类进行的任何动作。

本篇博客介绍的是 ETH 苏黎世联邦理工的研究团队在机器人顶刊Science Robotics上发布的成果,探索如何让拥有腿部和手臂的机器人(即腿足机械臂)学习并执行像羽毛球这样高度动态、需要全身协调的复杂技能。这篇论文不仅仅是让机器人学会打羽毛球,更重要的是它提供了一个通用的框架和方法,用于训练高自由度、多模态机器人执行需要精细全身协调的复杂动态任务,这对于推动通用型机器人的发展具有里程碑式的意

开源软件的低成本、可协作性和透明度等特点,使得越来越多的企业和个人选择使用开源软件,促进了软件行业的繁荣。因此,如何更好地利用开源软件的优势,发挥其推动技术创新和应用的作用,是当前热门的话题之一。比如,我们熟知的安卓系统(主要应用于手机、平板或者车机),Linux系统(主要应用嵌入式系统或者PC),都是典型的开源系统,包括后续也诞生了国产麒麟系统,华为的鸿蒙系统,都为广大的公司或者研究人员提供了一
