




- @HPC_factory
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1块500GB M.2 SSD系统盘+1块8TB SATA 企业级硬盘作为数据盘。1块1TB M.2 SSD系统盘+1块18TB SATA 企业级硬盘作为数据盘。1块1TB U.2 SSD系统盘+3块18TB SATA 企业级硬盘作为数据盘。2张NVIDIA Geforce RTX 4090三风扇版。4张NVIDIA Geforce RTX 4090三风扇版。NVIDIA Geforce RTX
提供PyTorch→ONNX单行转换命令(torch.onnx.export)学术研究(论文复现率超80%)与小规模模型训练(参数规模<10B):仅支持Transformer类模型(LLaMA/GPT系列):GGUF格式支持4-bit量化,ARM设备内存占用减少70%:ZeRO内存优化技术可将万亿参数模型分割存储于GPU集群。:QLoRA量化支持在24GB显存设备微调70B参数模型。:仅支持NVI

CNN,这位图像处理领域的明星,以其独特的卷积层、池化层和全连接层结构,成为了自动学习空间特征的佼佼者。BERT,这位基于Transformer架构的预训练语言模型,以其双向编码器和丰富的预训练方法,成为了自然语言理解领域的佼佼者。GAN,这位生成任务的魔术师,以其生成器和判别器的相互对抗,创造出了逼真的样本。RNN,这位时间序列数据的守护者,以其循环连接的神经元结构,捕捉到了序列数据中的时序依赖
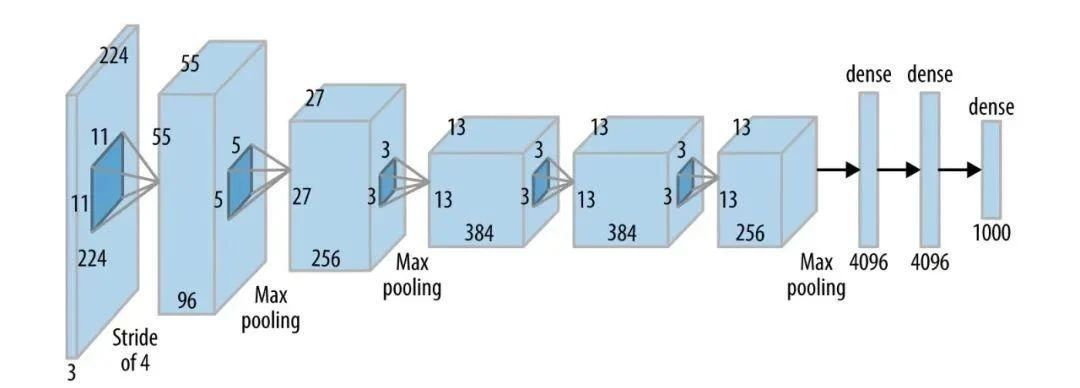
提供PyTorch→ONNX单行转换命令(torch.onnx.export)学术研究(论文复现率超80%)与小规模模型训练(参数规模<10B):仅支持Transformer类模型(LLaMA/GPT系列):GGUF格式支持4-bit量化,ARM设备内存占用减少70%:ZeRO内存优化技术可将万亿参数模型分割存储于GPU集群。:QLoRA量化支持在24GB显存设备微调70B参数模型。:仅支持NVI
提供PyTorch→ONNX单行转换命令(torch.onnx.export)学术研究(论文复现率超80%)与小规模模型训练(参数规模<10B):仅支持Transformer类模型(LLaMA/GPT系列):GGUF格式支持4-bit量化,ARM设备内存占用减少70%:ZeRO内存优化技术可将万亿参数模型分割存储于GPU集群。:QLoRA量化支持在24GB显存设备微调70B参数模型。:仅支持NVI
在多项基准测试中,Grok-3展现出了惊人的实力,刷新了数学(AIME 2024)、科学问答(GPQA)和编码(LCB)等领域的SOTA记录,大幅超越了DeepSeek-V3、Gemini-2 Pro和GPT-4o等模型。马斯克与三位xAI成员通过在线直播,正式官宣了Grok-3的全家桶阵容,包括Grok-3(Beta)、首个推理模型Grok-3 Reasoning(Beta)以及Grok-3 m

CNN,这位图像处理领域的明星,以其独特的卷积层、池化层和全连接层结构,成为了自动学习空间特征的佼佼者。BERT,这位基于Transformer架构的预训练语言模型,以其双向编码器和丰富的预训练方法,成为了自然语言理解领域的佼佼者。GAN,这位生成任务的魔术师,以其生成器和判别器的相互对抗,创造出了逼真的样本。RNN,这位时间序列数据的守护者,以其循环连接的神经元结构,捕捉到了序列数据中的时序依赖
等(推荐, 高性价比)
1块500GB M.2 SSD系统盘+1块8TB SATA 企业级硬盘作为数据盘。1块1TB M.2 SSD系统盘+1块18TB SATA 企业级硬盘作为数据盘。1块1TB U.2 SSD系统盘+3块18TB SATA 企业级硬盘作为数据盘。2张NVIDIA Geforce RTX 4090三风扇版。4张NVIDIA Geforce RTX 4090三风扇版。NVIDIA Geforce RTX
其中,CUDA开销通常为基础模型显存的15%,运算显存则包括KV Cache、激活值以及CUDA缓存,每个元素的字节数同样取决于所选精度。*最小推荐显存基于相应精度计算,包含CUDA开销和工作内存 **最小推荐显存(FP32)基于全量参数计算,包含CUDA开销和工作内存。*最小推荐内存基于相应精度计算,包含工作内存和系统预留 **最小推荐内存(FP32)基于全量参数计算,包含工作内存和系统预留。1
