
写文章




- @DeepLn_HPC
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
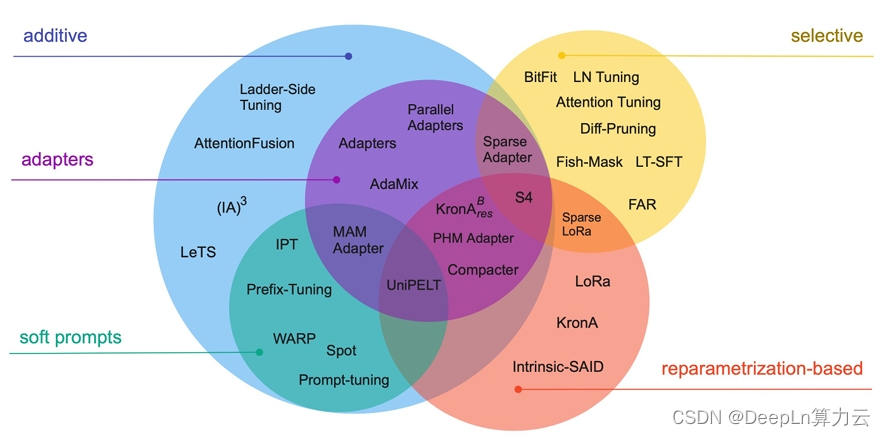
怎样用BitFit进行大模型高效微调——手把手DeepLn教程
参数高效微调是在对大型语言模型进行微调时的一种重要策略,它旨在改进模型性能的同时,尽量减少对额外参数的需求。通过冻结大部分参数,显存占用下降了5个G左右。训练时间由原来的50.53分钟降低到37.08分钟。
GPU租用为什么优选FunHPC乐算云(原DeepLn算力云)?
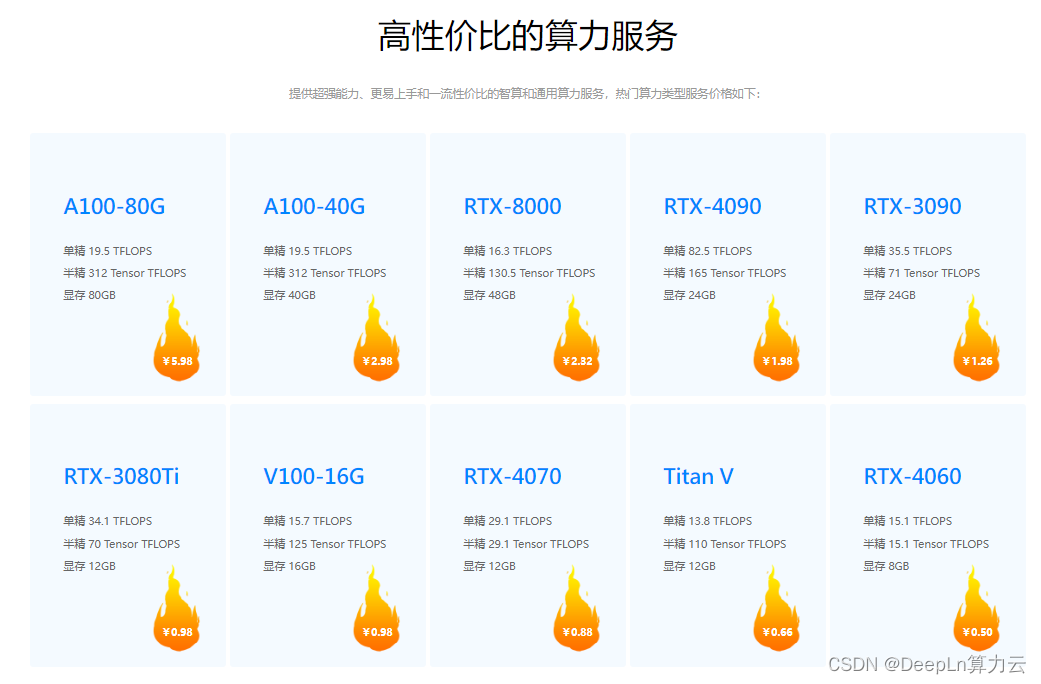
A100和RTX8000都2元档白菜价,32G显存的V100做到了1元档,以使深度学习和数据科学变得更加触手可及。
DeepLn算力云的便捷GPU租用是什么体验
主打超高算力、简单易用、高性价比,A100每卡时2.98元,4090每卡时1.98元,更有数十种优质算力可选,这么划算的云端算力,还不赶快来体验~

怎样用BitFit进行大模型高效微调——手把手DeepLn教程
参数高效微调是在对大型语言模型进行微调时的一种重要策略,它旨在改进模型性能的同时,尽量减少对额外参数的需求。通过冻结大部分参数,显存占用下降了5个G左右。训练时间由原来的50.53分钟降低到37.08分钟。
到底了