- @DeepLink_2025
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
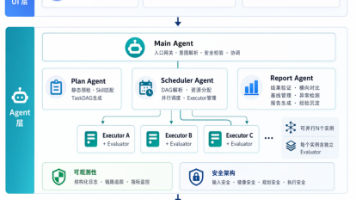
为解决传统AI评测人工成本高昂、技术门槛高、跨芯片适配难等痛点问题,DeepLink团队推出多智能体协作的自动化评测方案,构建多智能体协作机制,实现AI软硬件评测的全流程自动化,能够显著提升评测效率。此外,团队在近日开源了 AI 全环节软硬件验证技能库(DeepEval-Skills),作为验证平台的核心工具之一,DeepEval-Skills已适配多款国内外主流AI芯片,覆盖 NLP、CV、多模
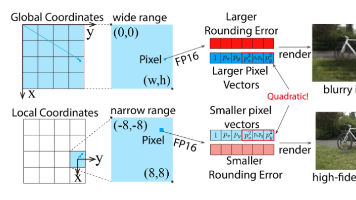
3D高斯泼溅(3DGS)凭借出色的渲染质量和速度,已成为三维重建、具身智能等领域的当红技术。然而,当场景规模扩大或分辨率升至4K时,即使3DGS也难以维持实时帧率。现有优化多从算法角度压缩高斯数量或简化光栅化,却忽略了更根本的问题:3DGS的渲染管线与硬件特性并不匹配。本文从硬件加速角度:将Alpha混合过程映射为矩阵乘法,让Tensor Core真正参与3DGS渲染,并设计G2L坐标变换解决FP
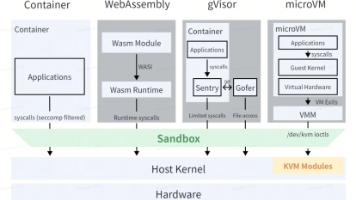
随着AI Agent从实验环境走向生产环境,Sandbox沙箱技术成为保障系统安全的核心基础设施。本文从“为什么需要”到“如何实现”再到“怎么选”:介绍 Agent Sandbox 的需求背景,在集群中如何提供规模化Sandbox 服务,最后探讨底层 Sandbox Runtime 技术路线并给出选型建议。
近日,上海人工智能实验室(上海AI实验室)升级并开源DeepLink多元算力混合推理技术方案,在此前仅支持多国产芯片的基础上,拓展NVIDIA 等芯片跨架构混合推理能力,满足多类推理场景需求。为便于方案落地,上海AI实验室联合八家国产芯片厂商推出标准化推理镜像,开发者下载即可快速部署;开源上述方案核心技术——智能流量路由系统DLRouter,助力行业低成本构建高吞吐、低时延的异构推理服务。

本文探讨了Agent时代存储优化的新思路。在上篇的基础上,下篇主要介绍运用超80万条文本片段进行的动态控制实验,基于Agent的局部性特征进行存储方案优化,成功提升了引用的效率,最终可以让模型容易进行引用而不是生成,从而让Agent执行任务变得更便宜。在本篇中详细介绍了在“紧凑布局”和“自适应索引”这两个优化方向上的探索与实验发现,并提出了在生产环境中的工程建议及未来优化方向!
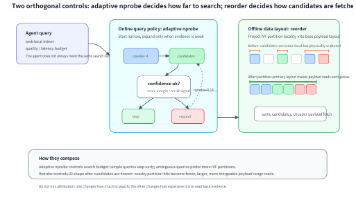
文章聚焦【Agent时代的存储】分上下两篇展开,本篇中首先描述了Agent的成本和稳定问题,挖掘这个问题的根因,讲讲为什么会选择存储作为答案。紧接着介绍业界火热的答案,展开分析方案中的核心贡献和关键矛盾,复盘借鉴推荐系统中的工程共识与和优化思路,聊一聊数据格式、搜索方案、优化假设等工作如何嵌入到大模型时代的存储方案中。在下篇中将会用一个简单的假设关联现有的尝试,选取业界共识的技术,在Agent典型

随着AI Agent从实验环境走向生产环境,Sandbox沙箱技术成为保障系统安全的核心基础设施。本文从“为什么需要”到“如何实现”再到“怎么选”:介绍 Agent Sandbox 的需求背景,在集群中如何提供规模化Sandbox 服务,最后探讨底层 Sandbox Runtime 技术路线并给出选型建议。
作者:YZY, QJW, ZYC, LHJ from DeepLink Group @ Shanghai AI Lab。
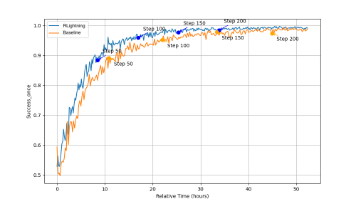
KernelSwift 把 “大模型偶尔写出好算子” 的偶然事件,变成 “持续、可复现、高性能” 的必然结果。其通过可控的优化迭代框架、分层的反馈体系、多样化的探索策略,让大模型真正成为算子优化的 “智能助手”,结合DeepLink芯片适配的基础和技术能力,既降低了底层优化的技术门槛,又持续推高 AI 系统的性能上限。未来,随着数据飞轮的持续转动,KernelSwift 还将在更多算子场景、更多硬

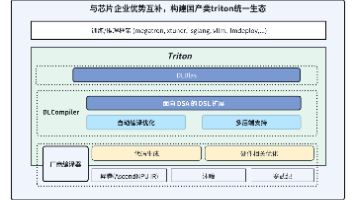
回顾过往技术实践过程,上海人工智能实验室(上海 AI 实验室)DeepLink 团队产出许多开源成果。2025 年 9 月,DeepLink 团队开源扩展的深度学习编译器,以及面向大模型训练与推理、异构硬件适配的高性能算库。开发者无需手动调优,即可获得接近硬件峰值的性能。面向架构,研究团队通过深度融合,在性能保持无损的同时,突破了跨代迁移难题。