- @CallMeYunzi
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1. 查看shutdown信息last -x shutdownlast -xlast -x | grep reboot发现是因为ubuntu kernal自动升级导致的。2. 关闭kernal自动升级(1) 查看 当前ubuntu kernal版本uname -r# 5.4.0-58-generic(2)关闭自动升级sudo apt-mark hold 5.4.0-58-genericDone..
cuda环境变量设置export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATHexport PATH=/usr/local/cuda/bin:$PATH
【代码】llama3.3 inference报错:Exception: data did not match any variant of untagged enum ModelWrapper。

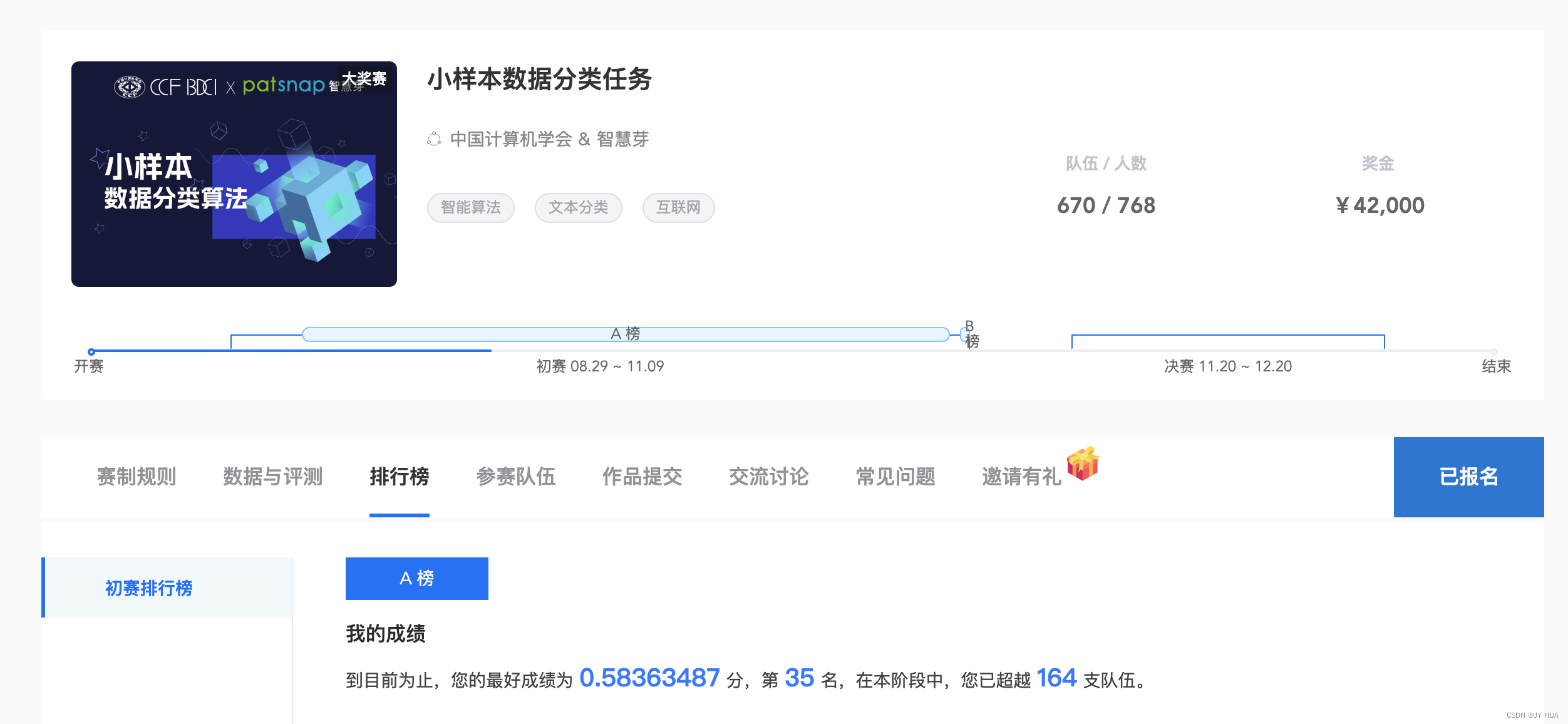
11.6B榜第50名进复赛??!掉的不行。。10.7上分,靠融合,xlnet、roberta、bert模型融合起来,强强联手,加gru,split_num设4,多折,文本清洗不如不洗,目前线上0.81770003,当前排名top99.14上分上分,血的教训,之前跑了十来版没怎么上分,事实证明!k-fold很重要!!!却也充满了随机性。。目前roberta+5fold线上0.80...
【代码】llama3.3 inference报错:Exception: data did not match any variant of untagged enum ModelWrapper。
# ref: <How to Fine-Tune BERT for Text Classification? ># 分层学习率衰减# 基础学习率lr_base = 5e-6lr_classifier = 5e-5# 衰减系数xi = 0.95lr = dict()lr[23] = lr_basefor k in range(23,0,-1):lr[k-1] = 0.95*lr[k].
RuntimeError: CUDA error: no kernel image is available for execution on the device卸载当前版本的pytorch, 重新按照以下安装pip uninstall torchpip install torch==1.7.0+cu110 torchvision==0.8.1+cu110 torchaudio===0.7.0
from transformers import BertModel, BertConfigconfig = BertConfig.from_json_file('bert-base/config.json')bert_model = BertModel(config, add_pooling_layer=True)pytorch_total_params = sum(p.numel() for

(Pandas: How to prepare a Multi-Label Dataset? )当进行mutli-class多标签分类任务的数据集构建时,通常我们会需要对如下这样的csv进行处理:使用sklearn中MultiLabelBinarizer,只需简单的四行代码,即可转换成模型所需要的数据集格式,具体代码如下:from sklearn.preprocessing...
这份baseline代码是对train数据集进行4:1划分train、dev,dev f1-macro为。整理代码中,顺手给大家整理了一份baseline代码可以作为参考。1. 加载 模型 & tokenizer。直接提交submit.csv文件,得分。4. 划分 train dev 数据集。,提交test 对应得分为。3. 构建输入输出文本。