




- @BigGod139
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
深度学习的有效性不是单一理论的支撑,而是**“底层数学理论(逼近、统计、优化)→中层设计思想(分层、聚焦、复用)→具体结构逻辑(感受野、残差、注意力)”** 的多层协同结果。理论是“指导”而非“万能公式”:所有理论都有假设条件(如万能逼近定理假设“激活函数连续”“紧集输入”),现实中需结合实验调整(如ReLU虽不连续,但实践中效果优于Sigmoid);实验是“验证与修正理论”的手段:如残差网络的提

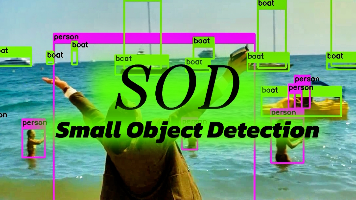
传统 YOLOv8 的 FPN 融合能力有限,难以保留浅层小目标的空间细节。SOD-YOLOv8 借鉴。传统 CIoU 损失在小目标边界框回归时,对中心点距离和宽高比例的惩罚不够直接,易导致定位偏差。:相比 CIoU,PIoU 对小目标边界框的微小偏移更敏感,定位精度提升约 1.1%~2.6%。:通过融合浅层高分辨率特征与深层语义特征,小目标定位精度提升显著。:动态调整不同通道和空间位置的特征权重

【代码】【YOLO脚本】数据集yaml文件检查。

都集中在中心,并且上下边缘都没有目标。testB的可能因为数据量少中心有些偏左上角。
本文介绍了一个可视化YOLO格式目标检测数据集的Python脚本。该脚本通过随机抽取3张图片,在图片上绘制对应的标注框和类别标签进行可视化展示。主要功能包括:获取图片路径和标签路径,随机选择样本图片,读取YOLO格式的标注信息,将归一化坐标转换为像素坐标,并在图片上绘制边界框和类别标签。结果显示为带有图片名称的标注可视化结果,适用于快速检查YOLO数据集标注质量。脚本使用了OpenCV和Matpl

本文介绍了一个可视化YOLO格式目标检测数据集的Python脚本。该脚本通过随机抽取3张图片,在图片上绘制对应的标注框和类别标签进行可视化展示。主要功能包括:获取图片路径和标签路径,随机选择样本图片,读取YOLO格式的标注信息,将归一化坐标转换为像素坐标,并在图片上绘制边界框和类别标签。结果显示为带有图片名称的标注可视化结果,适用于快速检查YOLO数据集标注质量。脚本使用了OpenCV和Matpl
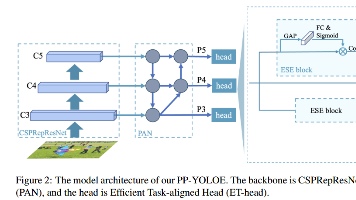
相比PP-YOLOE模型,PP-YOLOE-SOD改进点主要包括在neck中引入 Transformer全局注意力机制 以及在回归分支中使用 基于向量的DFL。Transformer在CV中的应用是目前研究较为火热的一个方向。最早的ViT直接将图像分为多个Patch并加入位置Embedding送入Transformer Encoder中,加上相应的分类或者检测头即可实现较好的效果。这里类似,主要加
摘要:该研究基于YOLOv11模型进行反无人机检测算法优化,对比了n-Scale和l-Scale两种模型配置。使用1万7千张训练数据,测试了不同参数设置对检测性能的影响。实验表明,调整置信度评分并未提升线上评测分数,而大模型虽参数量增加但需调整显存配置。评测指标包含检测精度(Precision/Recall/F1)、跟踪性能(MOTA/IDF1)及模型效率(FPS/参数量)。可视化结果显示检测准确

张祥雨是人工智能计算机视觉(CV)领域的杰出人才,现任旷视研究院base model组负责人、旷视首席科学家,也是西安交通大学人工智能学院兼职教授。张祥雨2012年毕业于西安交通大学软件学院软件工程专业,获学士学位,之后在西安交通大学与微软亚洲研究院控制科学与工程专业学习,于2017年获得博士学位。在学期间,他曾拿下美国大学生数学建模竞赛(MCM)特等奖提名奖,凭借此获奖经历获得微软亚洲研究院实习
传统 YOLOv8 的 FPN 融合能力有限,难以保留浅层小目标的空间细节。SOD-YOLOv8 借鉴。传统 CIoU 损失在小目标边界框回归时,对中心点距离和宽高比例的惩罚不够直接,易导致定位偏差。:相比 CIoU,PIoU 对小目标边界框的微小偏移更敏感,定位精度提升约 1.1%~2.6%。:通过融合浅层高分辨率特征与深层语义特征,小目标定位精度提升显著。:动态调整不同通道和空间位置的特征权重