




- @Ace_bb
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
自注意力机制(Self-Attention)虽然强大,但在实际应用中也存在一些问题,以下是一些主要问题以及相应的解决方案:1.

模拟退火算法什么是退火?退火是指将固体加热到足够高的温度,使分子呈随机排列状态,然后逐步降温使之冷却,最后分子以低能状态排列,固体达到某种稳定状态。物理退火过程加温过程一一增强粒子的热运动,消除系统原先可能存在的非均匀态;等温过程——对于与环境换热而温度不变的封闭系统,系统状态的自发变化总是朝自由能减少的方向进行,当自由能达到最小时,系统达到平衡态;冷却过程——使粒子热运动减弱并渐趋有序,系统能量
如何拟合逻辑回归模型的θ值这便是监督学习问题中的逻辑回归模型的拟合问题。我们有一个训练集,m训练样本,对每一个训练样本都用n+1维的特征向量表示,x0=1, y∈{0,1}。hθ(x)是假设的函数,θ是假设的参数。我们要解决的问题就是,对于给定的训练集,我们如何拟合参数θ?Cost函数分类问题的代价函数表达式在之前的线性回归方程中我们使用了这个代价函数:我们对这个代价函数进行如下更改...
描述性统计描述性统计是描述数据中的最大值,最小值,中位数,均值,方差,标准差等统计量。使用MATLAB进行描述性同济MATLAB中对应的函数如下:MATLAB代码及结果如下:使用EXCEL进行描述性统计使用EXCEL的数据分析工具也可以进行描述性统计使用SPSS进行描述性统计...
M1/M2/M3芯片运行缓慢。: pip安装时出现依赖冲突。: 模型加载需要很长时间。: 输出中文显示为乱码。
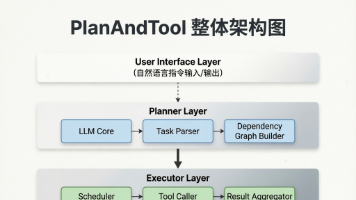
PlanAndTool框架是一种基于大语言模型的智能体架构,通过任务自动分解和动态执行规划解决传统LLM Agent系统的核心痛点。该框架融合了ReAct和Plan-and-Solve的思想,具备四大核心组件:规划器负责任务分解与计划生成,工具注册表管理可用工具元数据,执行器按计划调用工具完成子任务,状态管理器维护执行状态并支持持久化。相比传统单步调用模式,PlanAndTool显著提升了Agen
计算机语言现在计算机编程常用的语言是C,C++,Java等高级语言,但计算机第层是将高级编程语言的代码编译成二进制代码形式的指令才能执行。所以计算机语言中的基本单词是二进制形式的指令,一台计算机的全部指令称为该计算机的指令集。 二进制的指令是很难编写且理解的,所以在高级语言和二进制语言之间还有一个汇编语言,进行两者转换时的衔接。汇编语言与二进制语言存在着一一对应的关系。接下来要讲的指令就是汇编语言
NaN类型NaN 即 not a number 当某个计算值结果不为数值类型时就返回为NaN<body><script>console.log(Number("abc"));console.log(2/"aaa");//NaN类型不能与NaN类型比较,即不能和自己比较console.log...
ArrayList类什么是ArrayList类ArrayList是可以实现长度可变的数组存储在内的数据称为元素。此类提供一 些方法来操作内部存储的元素。ArrayList 中可不断添加元素,其大小也自动增长。我们知道定义的数组长度是不可以改变了,而ArrayList就客服了这点,可以根据需要随时添加元素,加长长度。JDK_API 中的 介绍如图:ArrayList的使用步骤三步:导包...
系统总线总线是链接多个部件的信息传输线,是各部件共享的传输介质。一条总线在同一时刻只允许有一个部件向总线发送信息,而多个部件可以同时从总线上接收相同的信息。总线实际上是由许多传输线或通路组成,每条线可一位一位的传输二进制代码,一串二进制代码可在一段时间内传输完成。存储总线: 连接CPU和主存的总线输入/输出总线: 连接CPU和各I/O设备之间的总线总线分类按连接部件的不同,分为三类总线:片内总线系