- @AUG2468
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
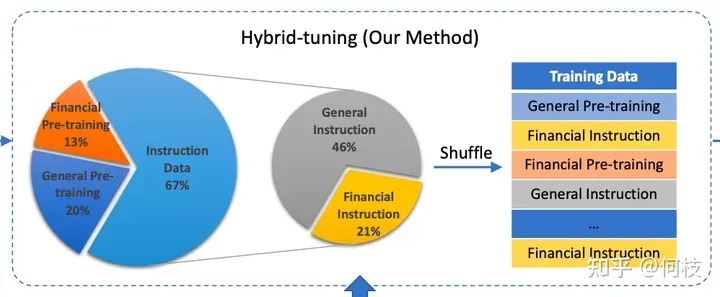
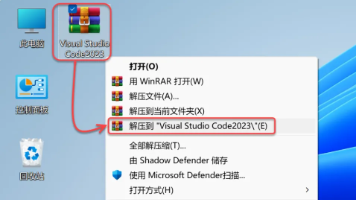
本文介绍了VSCode和PhpStorm两款开发工具的安装与配置方法。VSCode部分包含软件下载、安装步骤和中文语言包配置;PhpStorm部分则详细说明了安装流程、PHP环境配置及汉化插件安装。此外,文章还提供了网络安全学习资源包,包含视频教程、学习路线图和电子文档等福利内容。全文配有清晰的截图指引,适合开发者快速上手这两款工具。
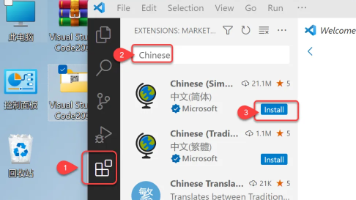
本文介绍了网络安全入门系列之HTML篇的工具安装教程,包含VS Code和PhpStorm两款开发工具的详细安装步骤。VS Code部分涵盖软件下载、解压安装、语言设置等完整流程;PhpStorm部分提供压缩包解压、安装路径选择等通用安装指引,并重点说明PHP运行环境配置方法,包括PHP路径设置和汉化插件安装。文末附赠网络安全学习资源包,包含视频教程、学习路线图、技术文档和面试题等福利资料。
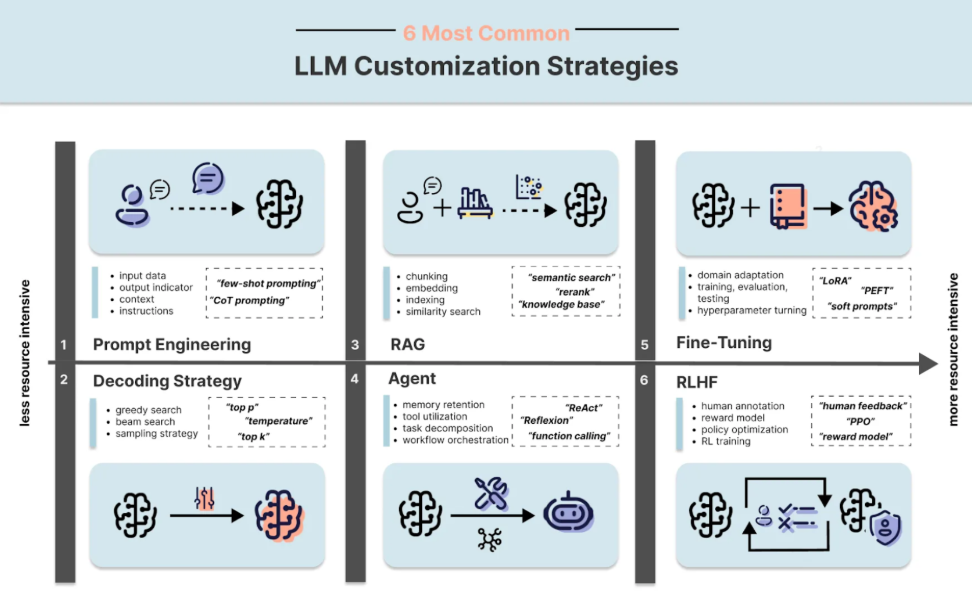
学习大语言模型(LLM)的路线可以分为多个阶段,涵盖基础知识、深度学习、自然语言处理(NLP)以及大语言模型的专门知识。

大语言模型(LLM)是基于自监督学习预训练的深度学习模型,训练数据量庞大、训练时间长,并且包含大量的参数。LLM在过去两年中彻底改变了自然语言处理领域,展现了在理解和生成类人文本方面的卓越能力。然而,这些通用模型的开箱即用性能并。LLM单独使用时无法回答依赖于公司专有数据或封闭环境的问题,这使得它们在应用中显得。由于从零开始训练一个LLM模型需要大量的训练数据和资源,这对于中小型团队来说基本不可行
语言建模的研究始于20世纪90年代,最初采用了统计学习方法,通过前面的词汇来预测下一个词汇。然而,这种方法在理解复杂语言规则方面存在一定局限性。随后,研究人员不断尝试改进,其中在2003年,深度学习先驱Bengio在他的经典论文《A Neural Probabilistic Language Model》中,首次将深度学习的思想融入到语言模型中,使用了更强大的神经网络模型,这相当于为计算机提供了更
在现代人工智能领域,算力扮演着推动创新、实现突破的核心驱动力。算力、算法、数据和系统架构等多个方面的综合优化对于大规模模型训练的成功至关重要。
复旦大学自然语言处理团队(FudanNLP)近期发布了一篇长达86页的综述论文,全面梳理了基于大型语言模型(LLM)的智能代理(Agent)现状。论文从AI Agent的历史出发,详细探讨了LLM-based Agent的背景、构成、应用场景以及代理社会等关键问题。作者们提出了一个由控制端(Brain)、感知端(Perception)和行动端(Action)组成的智能代理框架,并深入分析了每个部分

当地时间1月27日,纳斯达克股指出现3%下跌,原因是中国人工智能公司DeepSeek模型引发美国投资者关注。央视记者在纳斯达克交易所现场对纳斯达克副主席麦柯奕进行了采访。麦柯奕表示,他认为,DeepSeek将是人工智能领域革命的重要组成部分。冲击美股!DeepSeek崛起当地时间1月27日,美国股市开盘即大幅下跌,科技板块尤为惨重。市场分析认为,核心原因是中国人工智能初创公司DeepSeek的最新

AI大模型是指使用大规模数据和强大的计算能力训练出来的人工智能模型。这些模型通常具有高度的准确性和泛化能力,可以应用于各种领域,如自然语言处理*、图像识别、*语音识别等。

AI大模型是指使用大规模数据和强大的计算能力训练出来的人工智能模型。这些模型通常具有高度的准确性和泛化能力,可以应用于各种领域,如自然语言处理*、图像识别、*语音识别等。