




- @2501_92427005
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文将带你从零实现一个昇腾原生的Attention + LayerNorm融合算子,通过一次核函数调用完成两个计算阶段,实测在典型LLM推理场景下可进一步提升端到端性能15%-20%!全文包含完整的融合策略、双缓冲设计、向量化优化与性能对比分析,助你掌握算子级联优化的核心技巧。
本文聚焦于Scatter算子在NVIDIA GPU上的高性能Triton实现与深度优化。针对稀疏更新、图神经网络邻接聚合等核心场景,提出了一套涵盖原子操作优化、冲突消解、内存合并访问的完整解决方案。通过本文阐述的优化策略,在典型稀疏更新任务中,相比基础实现可获得最高4.1倍的性能提升,并将显存带宽利用率提升60%以上,为GPU上高性能稀疏计算提供了可复用的工程范式。
在当今的推荐系统、广告检索和自然语言处理应用中,EmbeddingLookup算子占据了超过60%的推理时间。这个看似简单的"查表"操作,实际上隐藏着深度的性能优化空间。本文将以华为昇腾NPU平台为背景,深入探讨如何通过算子融合、内存布局优化和硬件感知编程,将EmbeddingLookup的性能提升到极致。
在深度学习领域,矩阵乘法(MatMul)是最基础、也是最关键的操作之一。无论是 Transformer 的注意力机制、传统的全连接网络,还是卷积操作的底层实现,都绕不开高性能的矩阵运算。在昇腾 NPU 上开发一个高效 MatMul 算子并不是简单地把数学公式翻译成代码,而是要充分理解计算密度、内存带宽、硬件单元以及数据流调度等多维因素。

深入掌握Tiling策略设计、严谨的Shape推断以及规范的算子注册,不仅能帮助开发者高效完成算子开发任务,更能提升对异构计算系统整体工作流的深刻洞察。建议开发者在实践中,结合具体算子的计算特性和目标硬件,反复迭代优化Host侧的各项实现,从而真正释放昇腾AI处理器的强大算力。
本文将系统介绍 CANN 中 Ascend C 算子的 UT 测试体系,分析其设计思路、框架结构与执行流程,并通过一个完整示例展示如何编写、运行和分析算子的 UT 测试结果。
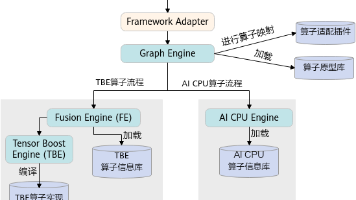
在昇腾 AI 生态中,CANN(Compute Architecture for Neural Networks)是连接 AI 框架与昇腾硬件的关键基础软件平台。随着昇腾硬件算力的不断提升,如何发挥 AI Core 的最大性能,成为算子开发者必须掌握的核心技能。其中,“Tiling(数据分块)技术” 与 “动态 Shape 支持” 是 Ascend C 算子开发体系的两大重点,也是各类认证考试的重

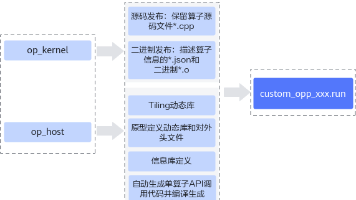
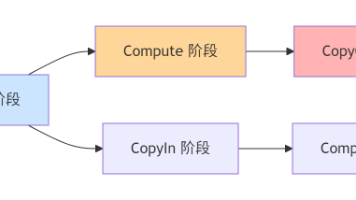
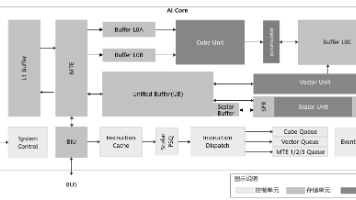
在 Ascend AI 处理器上开发高性能算子,往往不仅取决于算法本身的数学复杂度,更取决于开发者是否能充分利用芯片内部的存储结构、指令流水和多执行单元异步并行的能力。为此,华为 CANN(Compute Architecture for Neural Networks)提供了一套完善的算子编程范式,将硬件细节抽象为统一模型,帮助开发者快速构建高效、可维护的核函数。

硬件方面,开发者可选择Atlas 300I Pro推理卡或Atlas 800T A2训练服务器,并确保NPU状态正常。软件环境推荐使用CANN 6.3版本及以上,搭配Ascend C Toolkit。编译工具方面,CMake建议使用3.15+,GCC版本在7.3.0至9.4.0之间,以避免语法兼容问题。辅助工具包括npu-smi用于监控硬件状态、ascend-debugger用于内核调试,以及Go
本文介绍了基于Flutter与OpenHarmony的旅行记录应用开发实践,重点解析了旅行记录卡片组件的设计与实现。通过Card、InkWell和Column等Flutter组件构建层次清晰的卡片结构,采用Stack布局实现图片与信息的叠加展示,并详细说明了文本信息区的布局方法。文章指出卡片作为核心UI单元,需要平衡信息密度与视觉体验,在跨端开发中具有高度复用性和扩展性优势。最后强调合理的组件化设
