- @2501_91070801
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
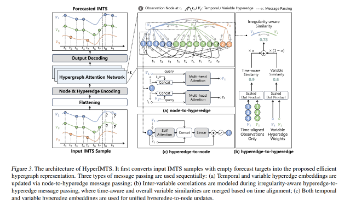
为解决不规则多元时间序列(IMTS)“变量内时间间隔不规则”与“变量间观测不对齐”的核心挑战,研究提出超图神经网络模型HyperIMTS。该模型无需数据填充,将IMTS观测值转化为超图节点,通过时间超边与变量超边构建统一关联结构,并借助节点-超边、超边-超边、超边-节点三类消息传递,结合不规则感知相似度融合机制,自适应捕捉时间与变量依赖性。
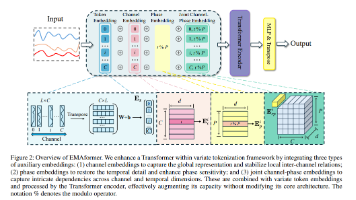
时间序列预测在能源、金融、医疗等领域至关重要,为此,时序即插即用模块应运而生,通过轻量化组件动态优化通道交互与特征表达,平衡性能与效率。其核心在于"动态适配"与"多域协同",研究者设计通用模块,在不改变主干架构的情况下增强模型自适应能力。未来,该领域将向多维耦合与可解释性深入发展,如融合时空图网络建模复杂系统,或通过频域可视化揭示决策逻辑。我这边也已经帮同学们,不想多花时间找资料的可以直接拿,希望
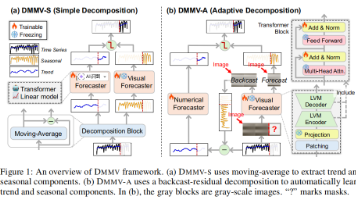
本文从理论和实验上证明,通过一个精心设计的分解框架,可以有效结合数值和视觉两种模态的优势,显著提升长时序预测的性能。其提出的DMMV-A模型通过新颖的自适应分解机制,成功克服了现有LVM方法中的周期性偏置问题,在多个基准测试中刷新了记录。这项研究不仅为时序预测任务提供了一个强大的新工具,也为未来如何将不同模态的大模型(如视觉、语言模型)应用于时序分析领域,开辟了富有前景的研究方向。
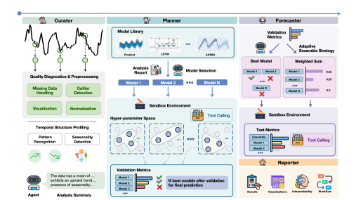
本文成功地提出了TimeSeriesScientist(TSci),这是一个创新的、端到端的自动化时间序列预测框架。理论上,它通过一种模仿人类专家的多智能体协作机制,实现了数据处理、模型选择、集成预测和报告生成的全流程自动化与智能化。实验结果也证明了它的强大实力,在多个标准数据集上,TSci的预测准确性显著超越了现有的统计模型和其他领先的大语言模型方法,同时其生成的报告在严谨性和可解释性方面也表现
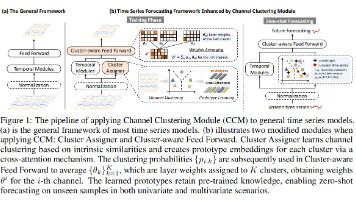
在数字化时代,海量复杂数据蕴含丰富时空信息,时间序列与时空数据融合研究成为解决实际问题的关键。传统时间序列分析仅关注时间变化趋势,忽略空间属性,难以精准刻画交通流量、气象变化等现实现象——这类现象既随时间动态演变,又受空间关联影响。物联网、传感器技术的发展提供了充足数据支撑,机器学习与深度学习算法的进步则为挖掘数据规律提供了有力工具。二者融合能更全面理解数据,提升预测准确性与可靠性,为城市规划、灾
本周精选9篇时间序列领域前沿论文,覆盖时序预测与趋势分析、时序异常检测与表征学习、时序生成与动态建模等其他方向。相关论文合集已经整理好,感兴趣的自取!

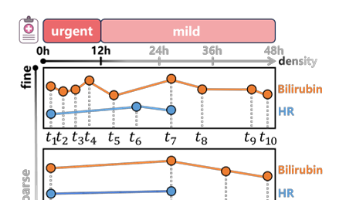
不规则多变量时间序列的预测任务在医疗、气象等领域至关重要,但其面临着采样间隔不均和数据缺失两大挑战。传统方法难以在稀疏数据中捕捉可靠模式,而现有的大型预训练模型多为规则采样数据设计。针对这些问题,研究者们提出了创新的解决方案。一篇论文(ReIMTS)通过一种递归多尺度建模方法,在不重采样的情况下,保留原始时间戳和采样模式信息,从全局到局部捕捉多尺度依赖。另一篇论文(VIMTS)则开创性地将视觉预训
多变量时间序列预测(MTSF)任务旨在基于过去L个时间步的C个变量/通道观测数据,学习函数fRL×C→RH×CfRL×C→RH×CYt1tHfXt−L1tYt1tHfXt−L1t其中,Xt−L1txt−L1xt−L2xtXt−L1txt−L1xt−L2...xt(历史观测序列,每个xt∈RCxt∈R。
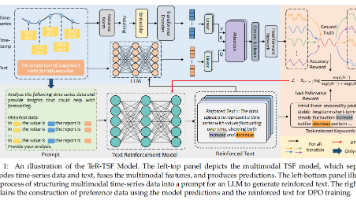
本文的研究结论非常明确:在多模态时间序列预测中,文本模态的质量至关重要。作者提出的TeR-TSF框架,通过一个由强化学习优化的LLM,将低质量的原始文本“提纯”为高质量的强化文本。这个强化文本不仅语义上与任务更相关,还能为预测模型提供关于数据动态的深刻洞见。实验证明,这种“先增强、再融合”的策略,能够稳定且显著地提升预测的准确性,效果超越了当前许多先进的方法。
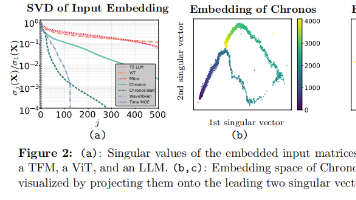
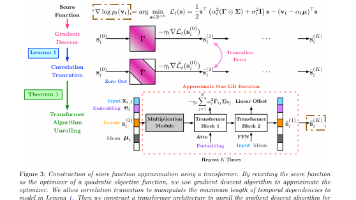
别再拿套壳LLM的思路做时间序列了:深挖Transformer的低秩坍缩与本质算力目前行业的绝对误区是:只要把时间序列做个Token化(无论是量化还是连续Patch),然后原封不动地扔进类似LLaMA或T5的Transformer架构里暴力预训练,大力就能出奇迹。大家在狂抄文本大模型的前馈层宽度、注意力头数和网络深度,将这视为Time Series Foundation Models (TSFM)