
写文章




- @2501_90713548
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
MOE-1 基本认识
MoE(Mixture of Experts)是一种深度学习架构,其核心思想是通过**多个专家网络(Experts)和一个门控网络(Gate Network)**来动态地选择和组合不同的专家,从而提高计算效率和模型能力。MoE 的核心组成专家网络(Experts)MoE 由多个**子神经网络(Experts)**组成,每个专家都是一个独立的子模型(通常是 MLP 或 Transformer 层)。

PPO to GRPO - 1
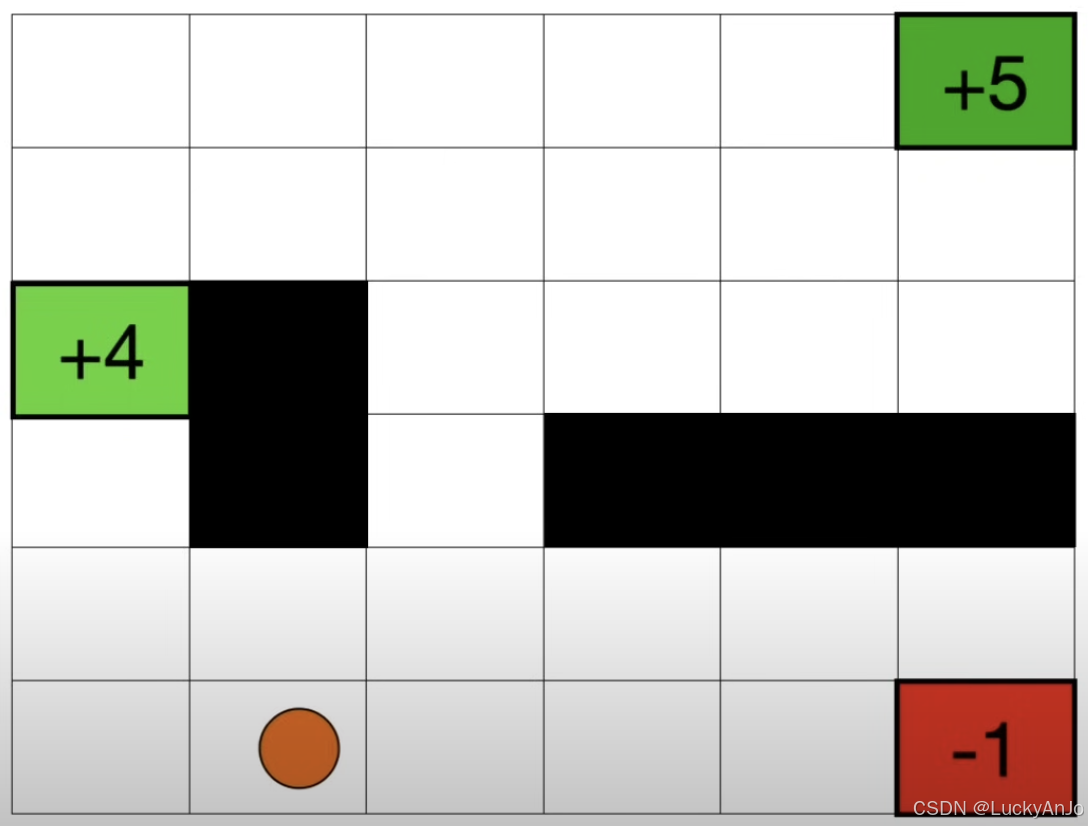
考虑一个网格迷宫游戏,智能体(Agent)初始位于网格中的一个随机位置,可以执行上下左右的移动动作。网格中存在障碍物、宝藏以及陷阱。智能体的目标是通过探索网格,获得最大得分。PPO(Proximal Policy Optimization)算法通过限制策略更新幅度,提供了一种更加稳定和高效的强化学习方法。在网格迷宫游戏中,智能体可以利用PPO算法平衡探索和利用,从而逐步学习到优化的行动策略。通过结
DPO vs PPO
DPO(Direct Preference Optimization)是一种基于人类反馈(Human Feedback, HF)直接优化大语言模型策略的强化学习方法。与传统的强化学习方法不同,DPO并不依赖于复杂的奖励函数,而是通过人类对模型输出的偏好评分,直接对模型进行微调。具体来说,DPO的核心目标是通过对比多个候选答案或策略,并基于人类的偏好反馈来优化生成模型。这一方法的优势在于,能够更直观
到底了