




- @2401_87177990
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文以生动比喻系统介绍了LangChain知识体系框架。文章将大模型应用比作森林,LangChain则是导航地图和工具包。内容分为六个层级:1)底层基础(LLM、Prompt、Embedding);2)核心模式RAG(检索增强生成);3)开发框架(组件化设计、LCEL语法);4)高级编排(LangGraph状态图、代理工具);5)服务部署(LangServe API化);6)运维监控(LangSm
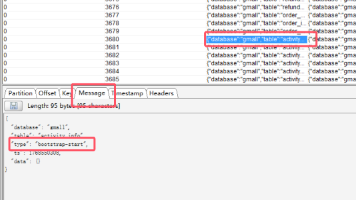
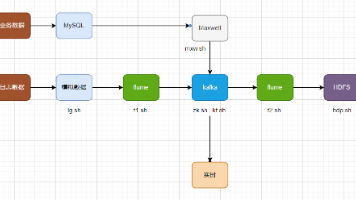
本文介绍了大数据项目中数据同步的操作流程:首先通过xcalljps命令检查服务进程,若无则使用zk.sh等脚本启动相关服务;其次详细说明了历史数据全量同步的概念和操作步骤,以activity_info表为例演示了使用Maxwell将MySQL初始数据同步到Kafka的过程,并解释了Kafka中数据条目多于源数据库的原因(包含界定全量数据的标志记录)。该同步机制既能保证Kafka拥有完整历史数据,又
本文介绍了将Kafka数据同步到HDFS的完整配置流程:1)配置Flume作业文件,定义Kafka Source、File Channel和HDFS Sink组件;2)解决日志数据零点漂移问题,通过拦截器修正时间戳;3)详细说明了自定义TimestampInterceptor拦截器的开发过程,包括Maven配置和核心代码实现;4)提供Flume启动/停止脚本;5)部署流程包括jar包放置、服务启动
本文详细介绍了数据仓库DWD层(数据明细层)的多域事务事实表设计,包括优惠券使用、商品收藏、页面浏览、用户注册和登录等核心业务场景。通过分层架构设计(ODS→DWD→DWS→ADS),实现了从原始数据到应用数据的完整流转。重点解析了各事实表的业务价值、数据装载逻辑和典型分析场景,如优惠券核销率分析、用户收藏行为分析、页面流量统计等。同时提供了数据治理方案(一致性检查、血缘分析)和性能优化建议(分区
本文详细介绍了用户维度拉链表的设计与实现方案。主要内容包括:1. 创建用户维度拉链表结构,包含用户ID、脱敏信息、开始/结束日期等字段,采用ORC格式存储并分区管理;2. 数据装载过程分首日全量装载和每日增量更新,通过start_date和end_date标记数据有效期;3. 实现数据脱敏处理,对姓名、手机号、邮箱等敏感信息进行保护;4. 采用分区设计(9999-12-31分区存最新数据,日期分区

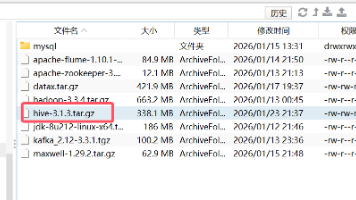
本文详细介绍了Hive的安装部署及元数据配置到MySQL的过程。主要包括:1)在hadoop102节点上解压Hive安装包、配置环境变量和解决日志冲突;2)将MySQL驱动拷贝到Hive目录,配置hive-site.xml文件连接MySQL元数据库;3)初始化元数据库、修改字符集后启动HDFS和Hive客户端。通过执行show databases命令验证安装是否成功。整个流程涵盖了从软件安装到元数
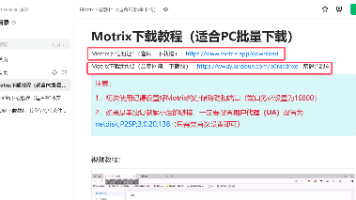
本文介绍了使用Motrix下载器解析网盘文件的详细步骤:1.访问指定网站并下载Motrix下载器;2.设置下载器参数(保存路径、监听端口16800);3.在网站输入网盘链接和当日解析密码;4.解析文件后通过Motrix批量下载。该方法可显著提高下载速度,适用于个人或他人分享的网盘文件下载。
本文以生动比喻系统介绍了LangChain知识体系框架。文章将大模型应用比作森林,LangChain则是导航地图和工具包。内容分为六个层级:1)底层基础(LLM、Prompt、Embedding);2)核心模式RAG(检索增强生成);3)开发框架(组件化设计、LCEL语法);4)高级编排(LangGraph状态图、代理工具);5)服务部署(LangServe API化);6)运维监控(LangSm
本文介绍了电商交易域核心事实表的设计实现,包括下单明细表(dwd_trade_order_detail_inc)和支付成功明细表(dwd_trade_pay_detail_suc_inc)。下单表记录SKU级别的订单明细,通过关联4个ODS表获取完整信息;支付表则需关联5个表,并只记录状态为1602的支付成功数据。设计亮点包括:维度退化减少关联、金额分摊便于分析、增量更新提高效率、状态过滤保证质量