




- @2401_86435672
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
很多商家,眼馋那些内容博主有免费流量,自己却没有做内容的能力,养一个人专门做内容,在目前降本增效的背景下,对商家来说也是不小的压力,**现在就可以通过扣子的图文创作助手,快速生成基础内容,它还能自动做好排版,自动发布到公众号的草稿箱,**你只需要发布就可以了,这就大大提高了内容创作的效率。难道不怕接客时胡说八道吗?所以,从现在开始,大家可以不用在远处观望AI大模型了,完全可以自己去扣子coze上体

并且,百度表示已经大规模押注智能体,如今基于文心大模型的百度智能体生态已经逐渐形成,智能体+搜索是百度用大模型重构搜索的重要方向,搜索将成为智能体分发最大入口。2024年1-5月,国内大模型项目中标公告已发布近260个,百度领跑中标单位排行,百度在主流大模型厂商中拿下最多中标项目数量(10个)、覆盖最多行业(8个)、中标金额总数最高(6400万+),三项第一,对应项目采购单位包括中华全国总工会、南

学习AI大模型不仅需要理论知识的积累,还需要通过实践来加深理解。上述十大网站提供了丰富的学习资源和社区支持,能够帮助你在AI大模型的学习之路上走得更远。希望你能充分利用这些资源,提升自己的技能,推动人工智能领域的发展。
在当今这个信息化迅速发展的时代,人工智能技术已经成为推动社会进步的重要力量。特别是在我国,AI大模型技术的发展速度令人瞩目,各种平台纷纷涌现,表现出强大的技术实力和广泛的应用前景。

在当前信息时代,大型语言模型(Large Language Models,LLMs)的发展速度和影响力日益显著。大模型强大的推理以及生成能力成为了搭建智能体的最好的组件。本内容来源于Datawhale的开源的“生成大模型基础(so-large-lm)”,一个致力于探索和理解大型模型发展的前沿课程:https://github.com/datawhalechina/so-large-lm通过该开源课

大型语言模型 (LLM) 的课程 路线图。

同时,魔方B4T将AI算法的生产、部署、运行与维护整合到一个平台上,配合智能分析盒,平台、硬件、服务,用户的算法需求可以在平台上一站式解决。通用大模型的“大”和“通用”看着诱人,但对于细分领域的B端行业客户,他们更需要的不是通用大模型的“全能”能力、综合技术上的碾压,而是模型的精度和质量,即能在具体需求上追求极致,可以实现功能最大化的产品。比如,即使同一品牌,几百款不同产品,具备不同的芯片、传感器

😝有需要的小伙伴,可以保存图片到wx扫描二v码关注免费领取【保证100%免费】🆓。

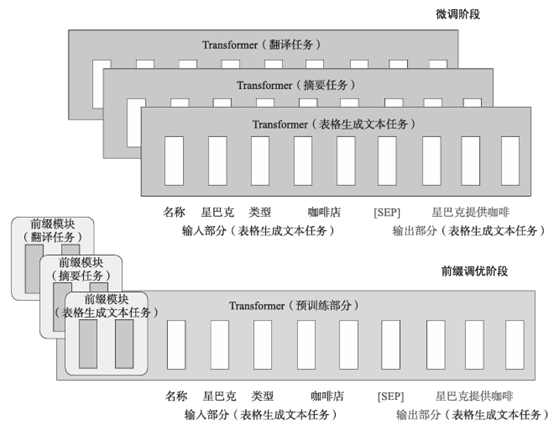
本文从背景、来源、技术路线及性能等方面综述了11种在模型参数调优阶段进行的方法,其中前缀调优、提示调优和P-Tuning v2属于引入特定参数来减少算力消耗、提升训练速度;基于LoRA的各种方法的基本思想是添加新的旁路,对特定任务或特定数据进行微调。
最近,程序员圈子里一个热门话题就是:“”有人说“”还有人无奈地说:“”甚至有人直接说:“这些曾经高薪的IT精英,怎么一下子沦落到卖保险、开滴滴的地步了?我们来听听几位转行程序员的亲身经历。小王,35岁,曾是某互联网大厂的Java开发工程师,年薪50万+。去年公司裁员,他成了“”下岗的一员。”小王苦笑道,“于是,小王通过朋友介绍,进入了保险行业。”小王说,“小李的经历更有意思。他原本是某电商平台的前
