




- @2401_85773359
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
,特指部分参数的微调方法,这种方法算力功耗比更高,也是目前最为常见的微调方法;除此之外,Fine-Tuning也可以代指全部微调方法,同时OpenAI中模型微调API的名称也是需要注意的是,OpenAI提供的在线微调方法也是一种高效微调方法,并不Fine-Tuning,是全量微调;微调, Fine-Tuning,一般指全参数的微调 (全量微调) ,指是一类较早诞生的微调方法,全参数微调需要消耗大量

可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。另一种类似应用的产品化建设思路,是大入口+小收费窗口的互联网模式,即整体产品免费,但一些特定的功能可能需要开通会员或者使用代币。这种“类视频电话”的大模型产品模式,本质上是将不同的 AI 感知、理解、生成能力进行融合,就像胡旋

写这篇文章的初衷:作为一个AI小白,把我自己学习大模型的学习路径还原出来,包括理解的逻辑、看到的比较好的学习材料,通过一篇文章给串起来,对大模型建立起一个相对体系化的认知,才能够在扑面而来的大模型时代,看出点门道。为什么要写这篇文章?首先我关注到了两个变化。
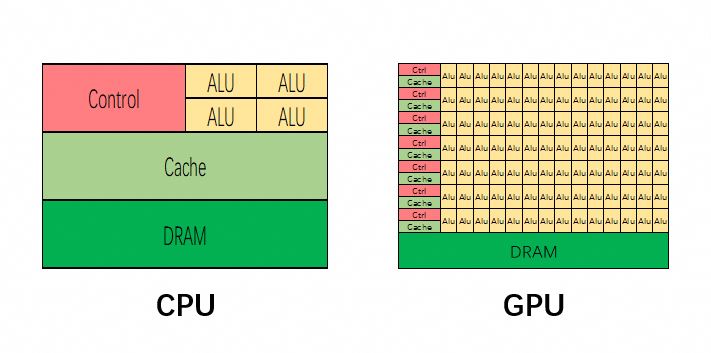
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。即更新模型所有权重的过程,被称为全微调。需要注意的是,与预训练一样,全微调需要足够的内存和计算预算来存储和处理训练过程中的所有梯度、优化器和其他更新组件。其中,大模型微调技术在此过程中起到了
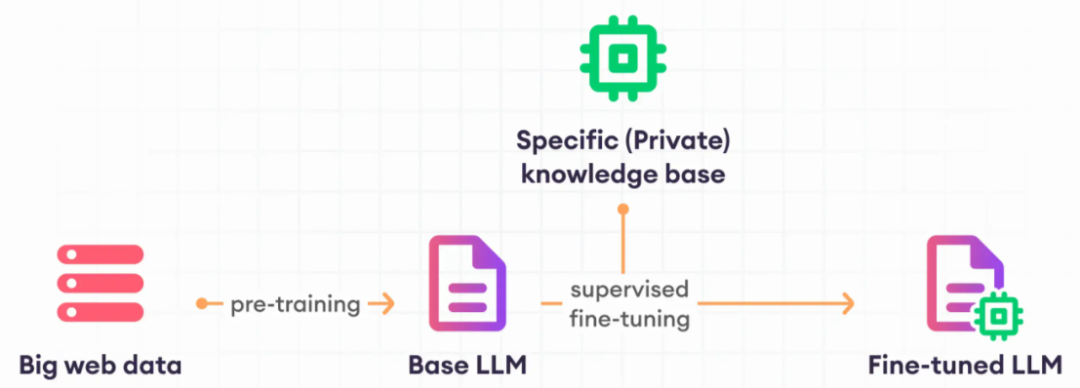
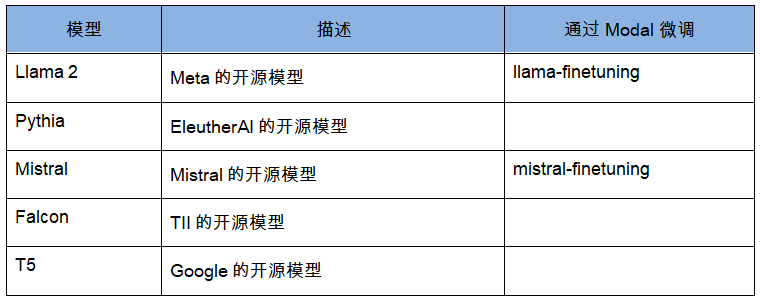
你可以根据特定的用例,通过微调大型语言模型的方式定制现有通用模型。为了更高效地微调模型,你可以考虑使用 LoRA 或模型分片(使用FSDP等框架)等技术。Modal的Llama和Mistral微调模板实现了许多这类的技术,能够帮助你快速启动分布式训练任务。你可以通过在 Modal 上微调 Llama 2 或Mistral 等开源模型获得一个定制的模型,这样不仅成本和延迟低于现有 API 服务,而且
部署一个自己的大模型,没事的时候玩两下,这可能是很多技术同学想做但又迟迟没下手的事情,没下手的原因很可能是成本太高,近万元的RTX3090显卡,想想都肉疼,又或者官方的部署说明过于简单,安装的时候总是遇到各种奇奇怪怪的问题,难以解决。本文就来分享下我的安装部署经验,包括本地和租用云服务器的方式,以及如何通过API调用大模型开发自己的AI应用,希望能解决一些下不去手的问题。
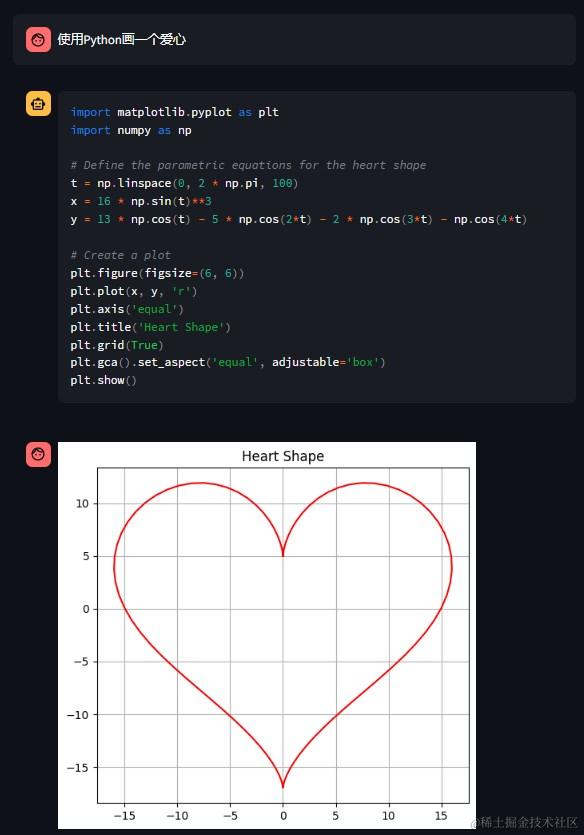
部署一个自己的大模型,没事的时候玩两下,这可能是很多技术同学想做但又迟迟没下手的事情,没下手的原因很可能是成本太高,近万元的RTX3090显卡,想想都肉疼,又或者官方的部署说明过于简单,安装的时候总是遇到各种奇奇怪怪的问题,难以解决。本文就来分享下我的安装部署经验,包括本地和租用云服务器的方式,以及如何通过API调用大模型开发自己的AI应用,希望能解决一些下不去手的问题。
部署一个自己的大模型,没事的时候玩两下,这可能是很多技术同学想做但又迟迟没下手的事情,没下手的原因很可能是成本太高,近万元的RTX3090显卡,想想都肉疼,又或者官方的部署说明过于简单,安装的时候总是遇到各种奇奇怪怪的问题,难以解决。本文就来分享下我的安装部署经验,包括本地和租用云服务器的方式,以及如何通过API调用大模型开发自己的AI应用,希望能解决一些下不去手的问题。