




- @2401_85737382
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
首先,我们需要从京东平台上采集手机品牌的相关数据。可以通过网络爬虫或API接口等方式获取数据。为了保证数据的完整性和准确性,需要设置合理的爬虫策略,并处理可能出现的反爬机制。

首先,我们需要从京东平台上采集手机品牌的相关数据。可以通过网络爬虫或API接口等方式获取数据。为了保证数据的完整性和准确性,需要设置合理的爬虫策略,并处理可能出现的反爬机制。
自定义调色板与风格Seaborn允许用户高度自定义图表的外观,包括调色板、风格等。# 设置调色板# 绘制箱线图plt.show()# 设置图表风格# 绘制箱线图plt.show()使用FacetGrid和PairGridFacetGrid和PairGrid是Seaborn中用于生成多图可视化的工具。FacetGrid:用于创建子图网格,可以展示数据集的不同子集。PairGrid:用于生成变量之间的
**cx_Oracle** 是一个 **Python 扩展模块**,它允许 Python 开发者访问 **Oracle 数据库**。使用 **cx_Oracle**,你可以执行 **SQL 语句**、**处理查询结果**、以及**管理数据库连接**等。以下是一些基本的 **cx_Oracle** 用法示例。
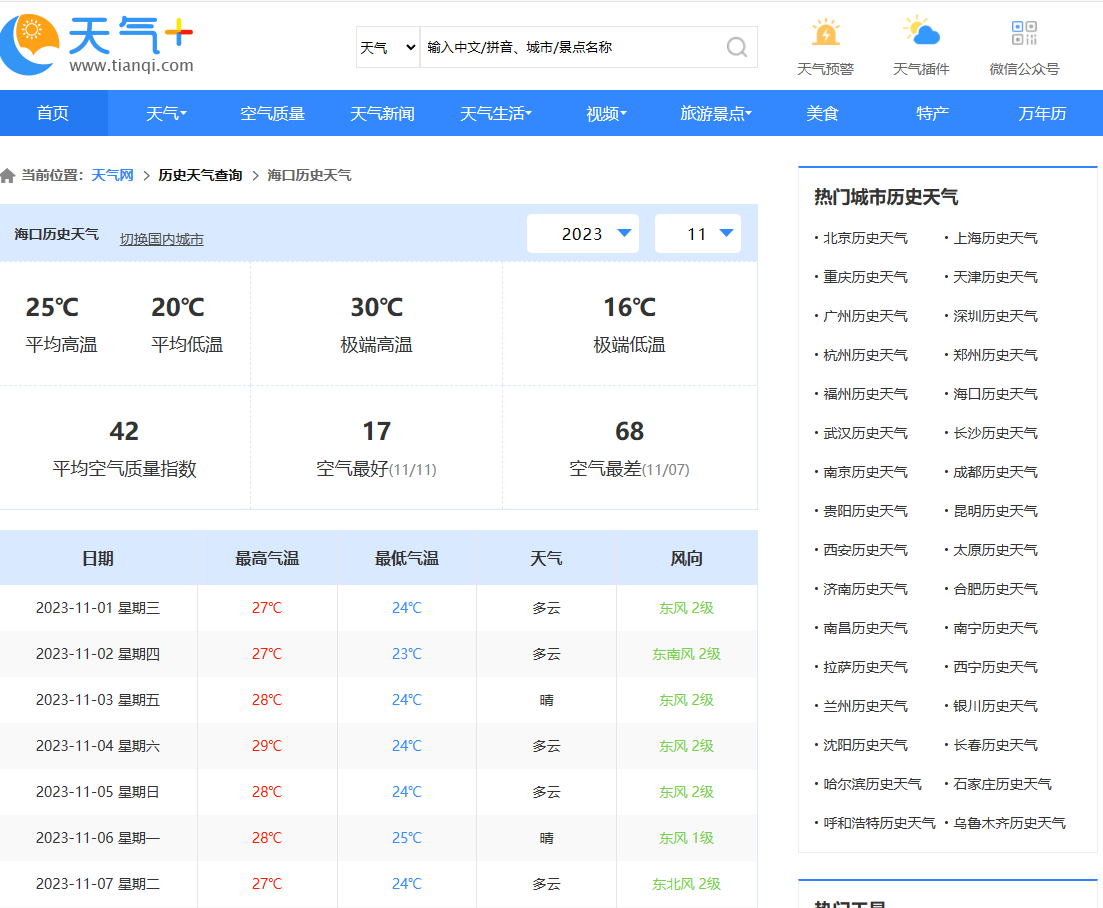
1.根据散点图的显示回归方:y = 0.6988742964352719x + 10.877423389618516来获取海口市11月份温度趋势2.根据饼状图可以了解海口市11月份的天气比例,多云天气占比为53.33%,晴天气占比为26.67%,阴天气占比为13.33%,小雨天气占比为6.67%,3.根据折线图了解海口市11月份的最高温度和最低温度趋势。4.根据词云图的显示,可以了解当月的天气质量
详细方面可见下方链接了解python为了区分python解释器的版本,所以需要在指定文件夹下的python.exe复制一份副本并重新命名环境变量要看仔细,如果系统环境变量有,用户环境变量里面就删掉反之,系统环境变量里面有,用户环境变量就删掉环境变量,一般自己的电脑只有一个用户,如果有多个用户建议添加到系统环境变量。
requests用于网络请求,pandas用于数据处理,matplotlib或plotly用于数据可视化。此外,为了处理时间序列数据,pandas的日期时间功能非常有用。先来看一下运行的结果。

pd.DataFrame(np.random.randn(100, 2), index=dates, columns=[‘A’, ‘B’]):生成一个包含100行、2列的随机数据框,并将其索引设置为日期范围。sm.tsa.ARIMA(data[‘A’], order=(1, 1, 1)).fit():构建并拟合ARIMA模型,其中order=(1, 1, 1)表示自回归项、差分次数和移动平均项的阶
实现思路:(1). 确定目标网站:掌上高考网站。(2). 分析网页结构:使用浏览器开发者工具查看网页源代码,分析大学数据的HTML标签和属性。(3). 编写爬虫代码:根据分析结果,使用Python的第三方库编写爬虫代码,实现对高校数据的爬取。(4). 数据清洗与存储:对爬取到的数据进行清洗和格式化处理,将数据存储到合适的数据结构中,如列表、字典等。(5). 数据可视化:使用Python的可视化库对
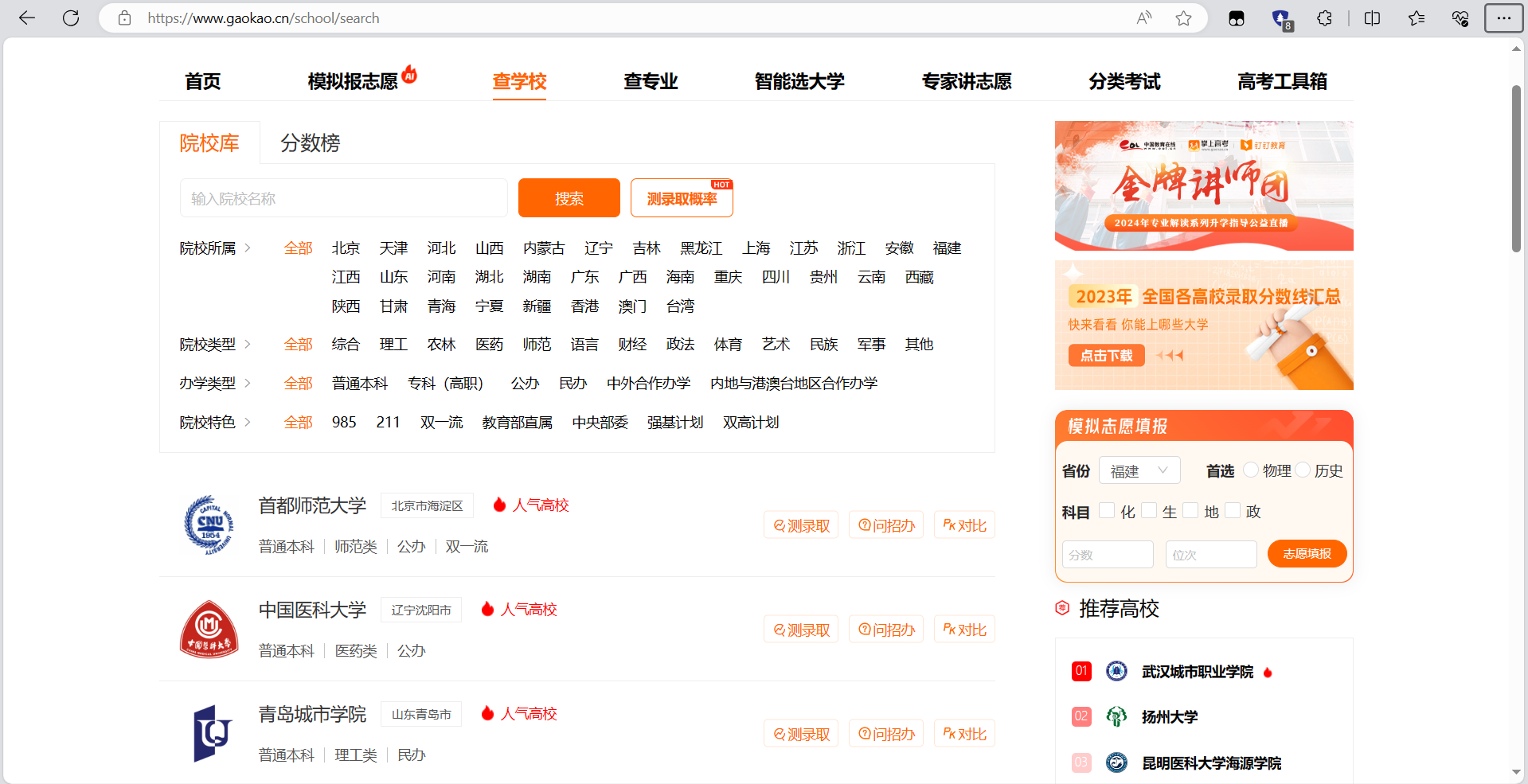
requests用于网络请求,pandas用于数据处理,matplotlib或plotly用于数据可视化。此外,为了处理时间序列数据,pandas的日期时间功能非常有用。先来看一下运行的结果。