




- @2401_84033492
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在探索最新的大语言模型(LLM)时,“MoE”这一术语频繁出现在各种标题之中。最近春招和实习已开启了。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。。
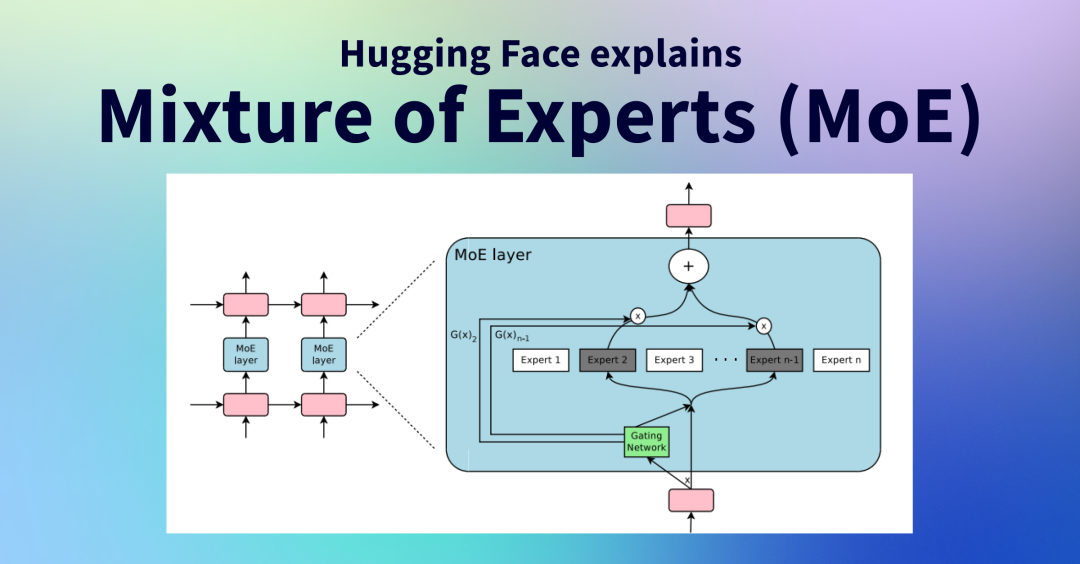
最近这一两周看到不少互联网公司都已经开始秋招发放Offer。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。。更多实战和面试交流,文末加入我们。
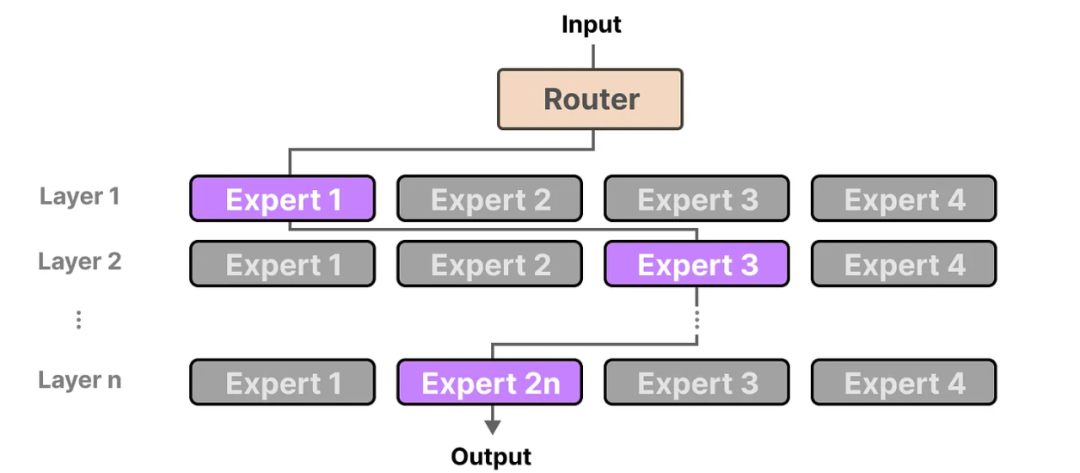
混合专家(MoE)是一种利用多个不同的子模型(或称为“专家”)来提升LLM质量的技术。MoE的两个主要组成部分是:专家:每个前馈神经网络(FFNN)层现在都有一组“专家”,可以选择其中的一部分。这些“专家”通常也是FFNN。路由或门控网络:决定哪些词元发送到哪些专家。在每个具有MoE的模型层中,我们会找到(相对专业化的)专家:需要注意的是,“专家”并不专注于特定领域,如“心理学”或“生物学”。专家
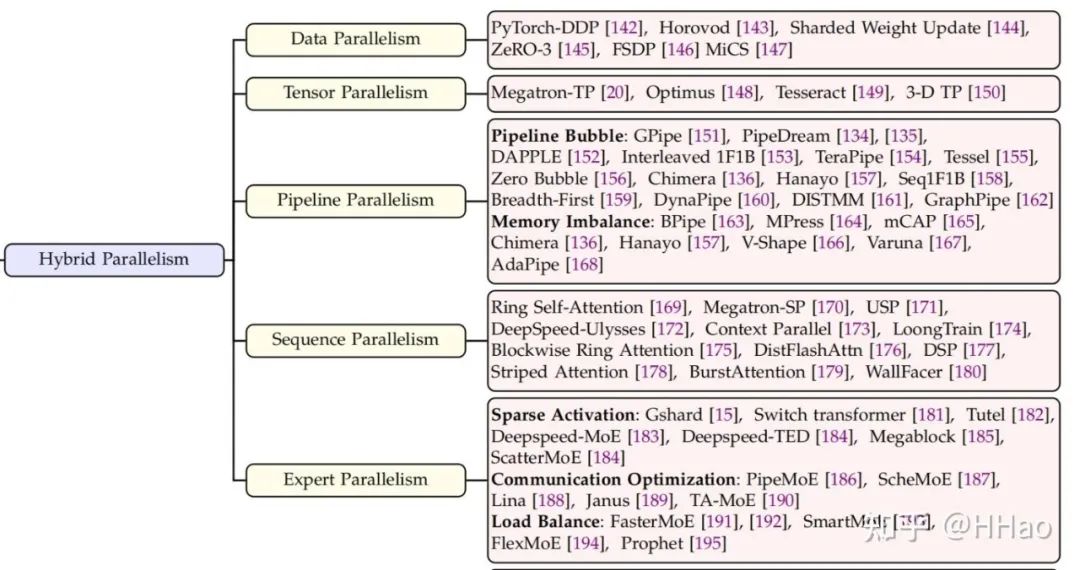
当前春招和实习已开启,但职场环境发生了变化,求职者增多,职位减少且要求更高。为帮助求职者应对技术面试,我们整理并发布了大厂面试题,包括《大模型面试宝典》2025版。此外,文章还介绍了大模型训练的并行策略,包括数据并行(DP)、流水线并行(PP)、张量并行(TP)、序列并行(SP)和专家并行(EP),并分析了它们的通信量及编排方式。这些策略有助于优化大模型的训练效率,尤其是在分布式基础设施上。
最近这一两周看到不少互联网公司都已经开始秋招发放Offer。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。。更多实战和面试交流,文末加入我们。
最近秋招发放Offer已高一段落。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。。更多实战和面试交流,文末加入我们。

最近这一两周看到不少互联网公司都已经开始秋招提前批了。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。

最近秋招发放Offer已高一段落。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。。更多实战和面试交流,文末加入我们。

RAG 是 “Retrieval-Augmented Generation”(检索增强生成)的缩写,它通过结合检索系统和生成模型来提高语言生成的准确性和相关性。RAG 的优势在于它能够在生成响应时引入外部知识,这使得生成的内容更加准确和信息丰富,对于处理需要专业知识或大量背景信息的问题尤其有效。随着大型语言模型(LLMs)的发展,RAG 技术也在不断进化,以适应更长的上下文和更复杂的查询。目前,大
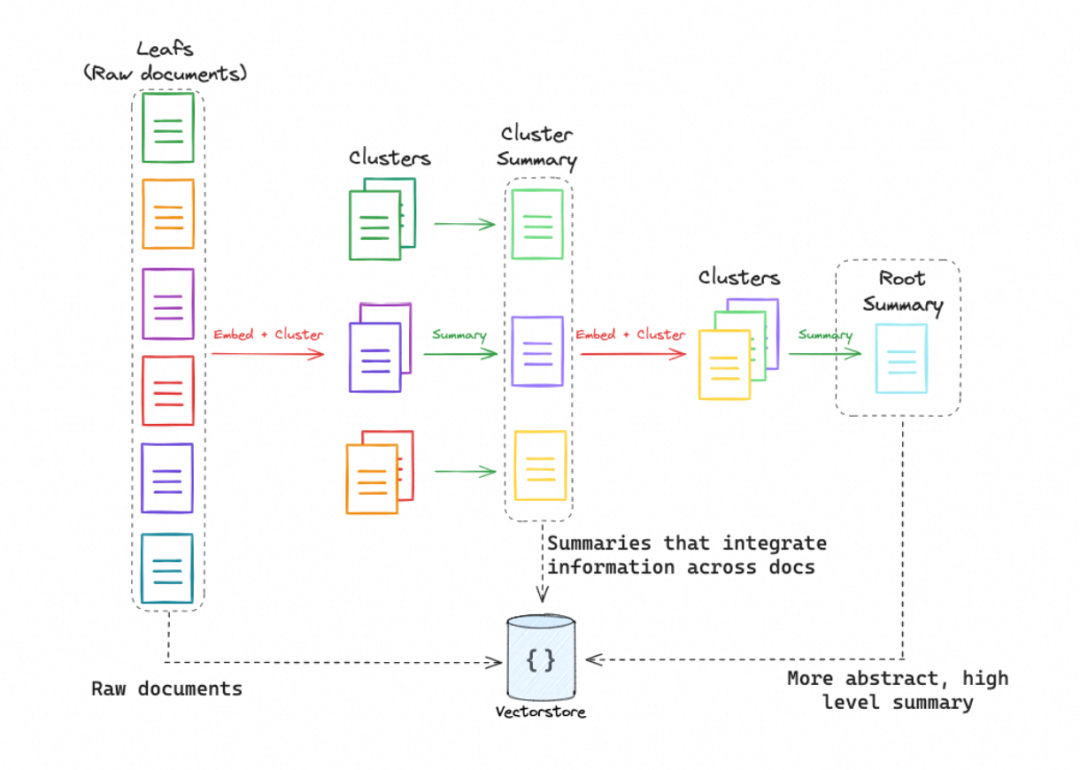
最近春招和实习已开启了。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。。
