




- @2302_79177254
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
作为一名常年折腾各类AI开发工具的技术博主,我一直有个疑问:现在的AI编程,到底是只能生成零碎代码片段,还是能真正落地完整可运行的Java项目?
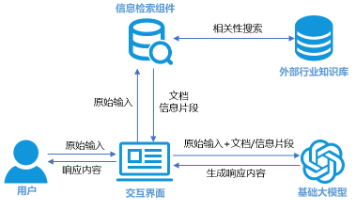
RAG(检索增强生成)技术采用“检索外部知识结合大模型生成”的混合架构,在企业问答系统、智能文档助手及研发知识库等实际应用中有效提升了回答的准确性和结果可解释性。该技术通过将权威数据集中存储在可控的数据库内,避免了传统方案依赖模型自身记忆的局限性。以openGauss的DataVec向量引擎为例,其实现了高效且可治理的向量数据管理,从技术层面解决了黑盒向量库常见的数据孤岛问题。
上周赶员工管理系统的课程设计,写到半夜时整个人都麻了:代码里变量名一会儿是 “state1” 一会儿是 “tempU”,三层 if-else 缠成了 “面条”,Spring Boot 启动还红一片 —— 这些 Java 里的 “日常麻烦”,以前要么蹲宿舍楼道问学长,要么啃俩小时文档,直到点开飞算那堆工具箱,再加上它跟 “搭子” 似的智能提醒,才发现这些破事儿居然能点一下就搞定。
做过运维的人大概都经历过这样的时刻:早上刚打开手机,就看到一堆未读消息。有人反馈网站打不开,有人说接口超时,还有人直接发来一句“系统是不是挂了”。最难受的不是修故障,而是发现自己是最后一个知道故障的人。很多问题其实早就有征兆,比如磁盘空间不足、服务异常退出、网络连接失败,甚至日志里已经连续刷了几十条 ERROR。但因为没人盯着日志,这些信号最终都被忽略了。有一次我排查线上问题时,发现日志里提前两个

最近AI助手确实火,大家也都愿意去试。但说实话,我身边很多朋友试了一圈下来,反馈都差不多:“装是会装了,但然后呢?到底怎么用才能真的省时间?”
在现代软件开发中,版本控制系统是不可或缺的基石。Git 作为目前最主流的分布式版本控制工具,其强大的分支管理、历史追溯以及协作能力,极大地提升了开发效率。本文将基于实际操作流程,深入剖析 Git 从仓库初始化、配置管理、核心区域交互到版本回退与文件操作的完整链路,并重点探讨其背后的工作原理。
在当前人工智能的浪潮中,大语言模型(LLM)驱动的智能体(Agent)展现了巨大的潜力。理论上,它们可以自动化执行任务、分析数据,成为我们的得力助手。但在实际开发和使用中,我们常常会遇到一个瓶颈:智能体似乎“不够聪明”,无法获取最新、最真实的数据。这篇将记录并分享如何解决这一核心痛点,通过将智能体与专业的网络数据采集服务(IPIDEA)相结合,从零到一构建一个真正具备全网数据洞察能力的“AI数据分
现在的工业物联网已经走过了单纯为了“记录数据”的阶段,企业更看重的是数据能多快被算出来,能多深程度地去指导业务决策。传统的时序数据库由于最初只考虑存储效率,在应对现在这种高并发计算、复杂融合分析的需求时,确实遇到了架构上的硬伤。DolphinDB 从设计之初就看到了这个瓶颈。它用存算一体的设计解决了数据搬运造成的延迟;用丰富的内置函数和多模态引擎去掉了对外部多套组件的依赖;用原生的流批一体和 AI
群消息不断弹出,私聊消息一个接一个,有时候刚回复完这个窗口,另一个窗口又冒出了新的问题。尤其是做社群运营、技术支持或者管理多个群聊的人,经常会产生一种感觉:时间不是花在工作上,而是花在回复消息上。

是ToDesk的核心基础设施。通用的视频编码标准(如H.264)是为视频会议和流媒体设计的,并不完全适配远程桌面的特殊需求——远程桌面的画面特征是大量静态区域(如窗口边框、桌面背景)加上局部高频变化区域(如鼠标光标、打字光标、视频播放区域)。观察返回的time数值,如果平均值超过50毫秒且波动很大(忽高忽低),说明你的基础网络质量不佳,这是后续一切优化的前提条件。你可以把远程控制想象成寄快递——有
