




- @2301_80395604
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
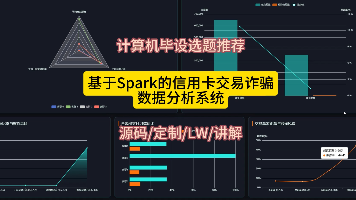
大学导师力推:基于Spark+Django的信用卡交易诈骗数据分析系统毕设首选毕业设计/选题推荐/深度学习/数据分析/数据挖掘/机器学习/随机森林/数据可视化
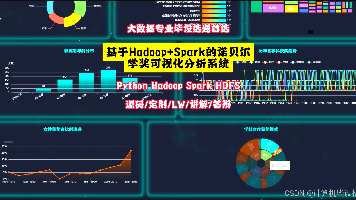
本文设计并实现了一套基于大数据技术的诺贝尔奖可视化分析系统。系统采用Hadoop HDFS存储海量历史数据,利用Spark进行高效数据清洗与统计分析,后端通过Django框架提供RESTful接口,前端结合Vue与Echarts实现动态图表渲染。重点实现了历年获奖趋势、获奖者年龄分布、国家科研实力对比及学科性别差异等功能的可视化展示,有效揭示了诺贝尔奖背后的科研发展规律与人才流动特征。
本项目基于Spark大数据框架,构建了一个淘宝电商用户行为数据分析与可视化系统。系统利用Python和Django作为后端,通过Spark SQL对海量用户日志进行高效处理,实现了流量统计、转化漏斗、RFM用户分群及商品热度分析等核心功能。前端采用Vue和Echarts将分析结果直观展示,为电商运营决策提供了数据支持。

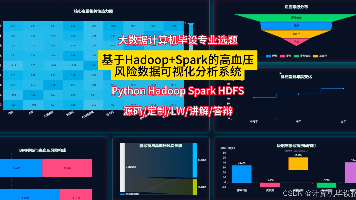
本系统围绕高血压风险预测,构建了一套完整的大数据分析流程。系统后端基于Python与Django,核心计算引擎采用Hadoop与Spark,对海量健康数据进行清洗、转换与多维度分析。研究内容涵盖人群基本画像、生活习惯、核心生理指标及多变量综合关系探索,最终通过Vue与Echarts将复杂的分析结果以交互式图表形式呈现,为理解高血压风险因素提供数据支持。
这是一个基于Hadoop和Django的毕设项目,主要对天猫订单数据进行可视化分析。后端用Spark处理海量数据,前端用Echarts画出销售趋势、地域分布等图表,帮你把复杂的数据看得明明白白。
本项目设计并实现了一个基于Spark的王者荣耀账号交易信息可视化分析系统。系统利用Hadoop与Spark大数据技术栈,对海量交易数据进行高效处理与多维度分析,探究了贵族等级、皮肤数量、安全属性等对账号价格的影响,并通过聚类算法挖掘高价值账号特征,最终以可视化图表形式直观展示市场规律,为玩家交易提供数据参考。

设计并实现了一个基于Hadoop+Spark的肥胖风险分析与可视化系统。系统采用Python语言及Django框架,利用Spark SQL对存储于HDFS的健康数据进行高效处理与分析。功能涵盖人口统计学、饮食习惯、生活方式等多维度与肥胖关系的探究,并通过Echarts实现数据可视化。该系统验证了大数据技术在健康风险分析领域的应用可行性。
本课题设计并实现了一个基于Spark+Django的全球旅游体验评价数据分析系统。系统利用Hadoop生态存储海量评论数据,通过Spark进行高效的多维度分析,如目的地热度、季节性偏好、预算与满意度关系等。后端采用Django框架提供数据服务,前端通过Echarts实现数据可视化,旨在为旅游决策提供直观的数据支持。

错过再等一年!这个自带5大分析维度的电商物流大数据分析系统(高分必备)你的毕设为什么总被导师打回?看看这个基于Hadoop的电商物流分析系统就懂了985导师都认可的大数据毕设:基于Hadoop+Java的电商物流数据分析与可视化系统
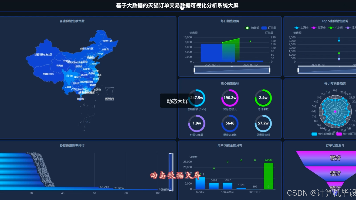
为应对城市交通挑战,本系统设计并实现了一个基于Hadoop与Spark的城市交通数据可视化分析平台。系统利用HDFS存储海量交通数据,采用Spark SQL及Pandas进行高效的数据清洗与多维度分析,涵盖客流时空分布、拥堵状况剖析、外部因素影响评估及城市交通模式聚类。后端基于Python与Django框架,前端采用Vue与Echarts实现数据可视化。该系统为理解城市交通运行规律、辅助管理决策提
